 James Walker
James Walker
Automate Oracle FLEXCUBE testing
Banks globally rely on Oracle FLEXCUBE to provide their agile banking infrastructure, and more today are migrating to FLEXCUBE to retain a...



![]() AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
![]() Test Case Design Generate the smallest set of test cases needed to test complex systems.
Test Case Design Generate the smallest set of test cases needed to test complex systems.
![]() Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
![]() API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
![]() Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
![]() Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
![]() Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
![]() Data Masking Identify and mask sensitive information across databases and files.
Data Masking Identify and mask sensitive information across databases and files.
![]() Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
![]() Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Help & Support Find a solution, request expert support and contact Curiosity.
Help & Support Find a solution, request expert support and contact Curiosity.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
![]() Integrations Explore Modeller's wide range of connections and integrations.
Integrations Explore Modeller's wide range of connections and integrations.
![]() Meet Our Team Meet our team of world leading experts in software quality and test data.
Meet Our Team Meet our team of world leading experts in software quality and test data.
![]() Our History Explore Curiosity's long history of creating market-defining solutions and success.
Our History Explore Curiosity's long history of creating market-defining solutions and success.
![]() Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
![]() Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
![]() Careers Join our growing team of industry veterans, experts, innovators and specialists.
Careers Join our growing team of industry veterans, experts, innovators and specialists.
![]() Press Releases Read the latest Curiosity news and company updates.
Press Releases Read the latest Curiosity news and company updates.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Contact Us Get in touch with a Curiosity expert or leave us a message.
Contact Us Get in touch with a Curiosity expert or leave us a message.

Software development has been revolutionized by new methodologies and practices. The software industry has moved from sequential waterfall approaches — where software requirements were pre-defined, coded, tested, and eventually released, often years later — to rapid evolutionary development of a minimal viable product, often over a period of weeks or months. The advantage of these new methodologies has meant we can unlock value earlier and obtain valuable feedback with which to test hypotheses and drive future releases.
Not only have the methodologies for building software changed, but the underlying technology we use to construct software has also changed with them. Notice, the word “construct” and not “build.” Modern software development has evolved to writing abstract tasks on-top of several layers of abstraction, binding together third-party libraries/APIs and defining a few custom pieces of business logic which define the Intellectual Property of an application.
These revolutions have enabled software to be developed at incredible and previously unknown rates. Virtually every company is now transforming into a software organization, with the biggest companies in the world leveraging software to drive new efficiencies, widen profit margins, and create new markets. While the effect has been disruptive (some referring to this era as the third industrial revolution), testing practices have not adapted at the same pace as development methodologies.
Testers face a continuous battle to keep up with the ever-increasing rate of change of software. Each time a new story passes through development, testers must:
In my previous article, I discussed how to use git for maintainable test automation from an operational perspective. This article will again consider lessons that testing might learn from development principles, now that test automation has aligned testing and coding more closely. In particular, we’ll take a deep dive into the architecture of the underlying automation framework, considering what constitutes a consistent and logical structure for continuous test automation.
Orderly and maintainable structure is necessary for test automation that can adapt rapidly to Agile software development, where the application changes with each release. It is also necessary for automation that is scalable, capable of dealing with the growing complexity of the application as new features are incrementally made available.
One of the design patterns widely considered as the de facto methodology for functional test automation framework is the Page Object Model, or “POM,” for short. Firstly, we’ll deep dive into this design pattern, exploring what it is and why you might use it, before discussing what makes a good page object, along with the different types of page objects. Finally, we’ll finish up by illustrating how page objects can be applied beyond the realm of functional UI automation, in other layers of testing like API and performance testing.
The page object model is a design pattern which promotes reusability and modularization of automation objects within a test automation framework. Largely this introduces design principals from the object-oriented software development world to the realm of test automation.
A page object is, in essence, an object-oriented class which exposes actions and activities that can be performed on a component or page of the system under test. One example might be a page object for the login module of the system which contains actions like entering a username, clicking login, etc.
The collection of page objects is called a page object repository which contains all the page objects for automating the system under test. A general principle is to decompose the page objects into a logical structure that maps to the structure of the application we’re testing. For a website that could be each page, or modular component within that page (forms, navigation bars, etc):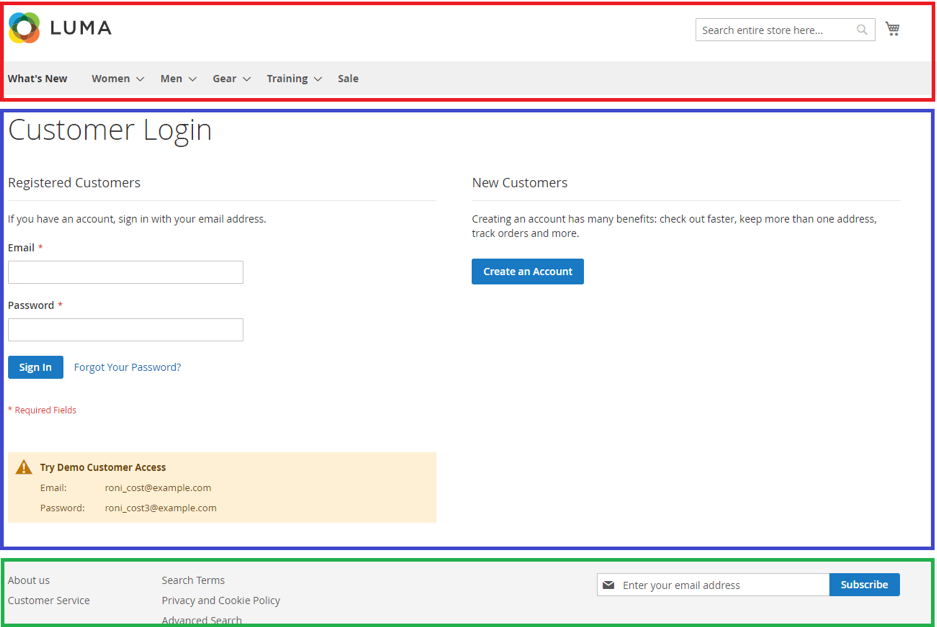
Figure 1: This page is decomposed into three-page objects – (i) The navigation bar (red),
(ii) the login screen (blue), and (iii) the navigation footer (green) which are distinct
components utilized across the application.
We want to promote as much reusability, and as little duplicated effort as possible. A good strategy for creating page objects is to work backward, not forwards. That is, construct the page objects as you go through creating your test scenarios, and only expose actions that are necessary for your test scenarios. Otherwise, you end up with a lot of code not being used and of little value to the framework.
The underlying test scripts are kept isolated, creating new instances of each of the page objects required in our test scenario. The test script then makes sequential calls to each of the methods. The chaining together of these methods from each page object forms our test case. The main benefit here is that if the user interface in our application changes, there is one single point of entry (the page object) that needs updating in one place. This is far quicker and simpler when compared to checking every test script, identifying whether it is impacted by a change, and then updating each one in turn: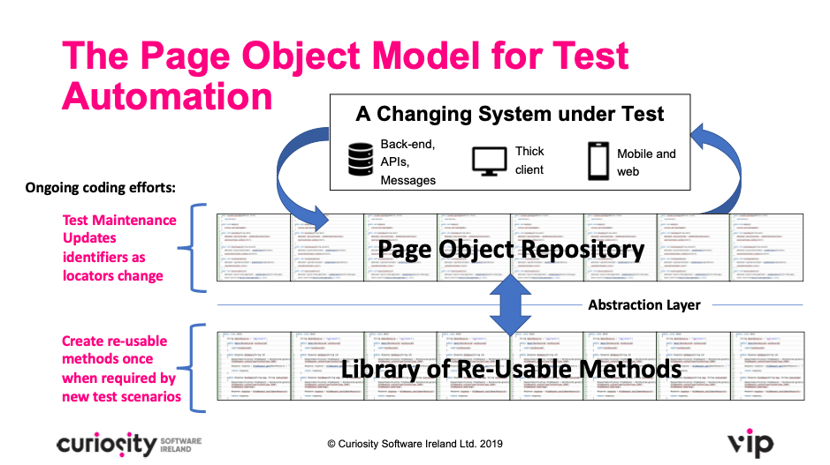
Figure 2: Reduced test maintenance efforts, by virtue of the abstraction between
fast-changing page objects and re-usable method.
Over the past decade, we have seen the testing industry move between numerous trends for test automation creation. Keyword driven automation/scriptless frameworks is a recent trend that has seen many failures within organizations. The increasing problem with these types of frameworks is that applications are complex and aren’t necessarily as simple as clicking a few buttons and entering the text within a form. Often, decisions we make later in an end-to-end scenario will be dependent on data or decisions made previously. In such scenarios (which are very common on any real-world application with embedded rules), custom code must be implemented.
We are now seeing the rise of the automation framework which is entirely code based, with a view to tackling the problem of application complexity. This is something that can’t be addressed by scriptless frameworks unless significant customization takes place. This customization defeats the purpose of such frameworks.
The page object model allows us to embed custom code within each method and abstract away from it. Each method may be performing trivial actions against a UI, or might feature complex code which is performing advanced operations like going into backend databases, performing API requests, handling email approvals, spinning up environments, and more. The key premise is that the page object model facilitates and hides the complexity of the routines taking place and exposes them in an elegant interface that can be used in a test scenario with ease. This abstraction is the power of a code-based automation framework coupled with the page object model, the only real viable option when building test automation for complex systems.
Because of the reusability and modularization it introduces, the page object model creates scalable frameworks that are agile to changes made in each release of the application.
Let’s first consider a trivial automation script that has been created without the page object model. The test scenario will usually consist of a series of linear steps directly embedding the automation actions into the code (see below). This is how beginner developers’ first projects tend to look before they understand the nature of object-oriented programming. As you can see the locators and actions are directly defined in one big script. Also, note it’s not inherently easy to read and understand what this JavaScript is doing: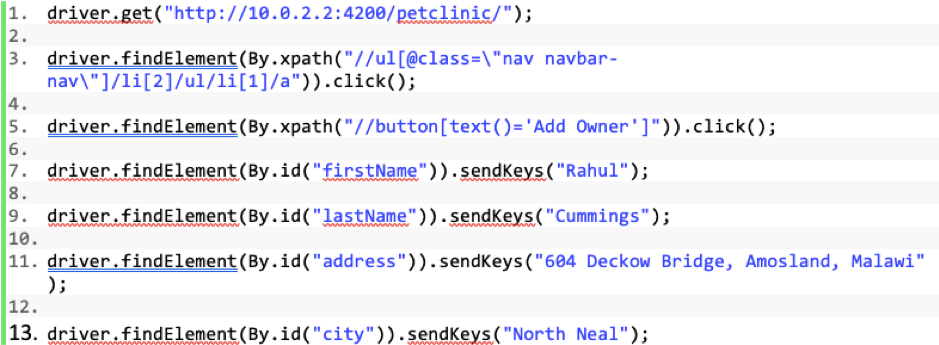
Figure 3: A trivial automation script created without following the page object model.
If any of the elements change and the locators are no longer valid we must scan through each test script to find the affected components and update them one by one in many locations.
Using the page object model, we abstract from this direct connection to the automation execution engine. The logic is instead embedded inside a page object, so we only make the change on one instance referring to actions we perform on each of the elements. Note this code also is easier to interpret, understanding what the test is performing: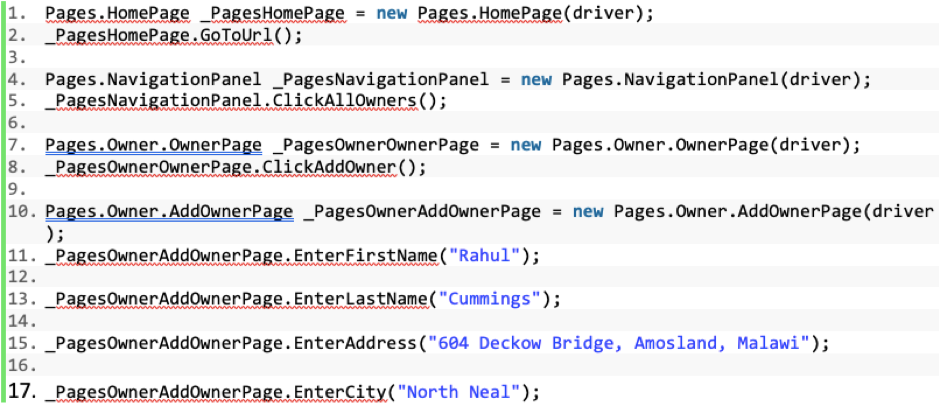
Figure 4: The same trivial automation script, created using the page object model.
In this world of POM, if an element changes and the element locator is no longer valid we only must update the relevant location within the page object in one singular location. This is a huge time-saving feature brought about by decomposing the framework into logical components; for those from a development background, this will ring true of object-oriented programming design principles.
Page objects can be implemented in any object-oriented programming language. In this article, we’ll be looking at a Java-based page object, but this is largely synonymous across any object-oriented languages, including C#, JavaScript, and Python-based test automation frameworks.
A page object is typically created for each module of the application. The identifiers for the page object are expressed at the top of the class. These contain the various locators and strategies for extracting the elements within the page represented by the class. In the example below, the test is using Selenium to test a web application, so our locators are using strategies for extracting elements from an HTML page using XPaths: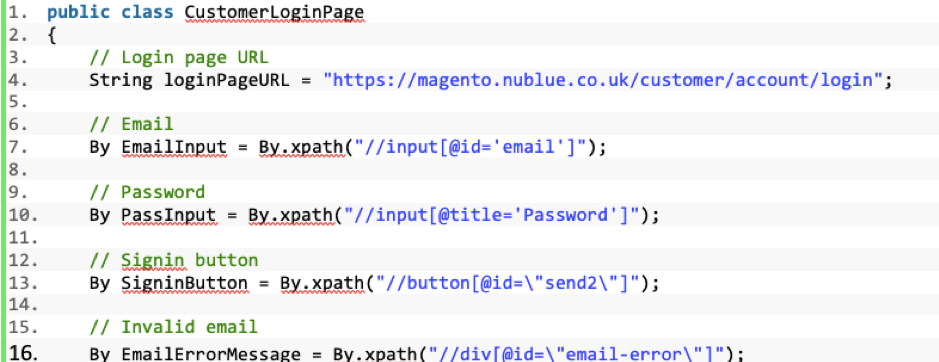
Figure 5: An example page object, written in Java for a web UI.
Within the page object, we then have the functions made available which can be performed on the page. These may be UI activities, like clicking and entering text, and assertions to assert specific states of the application. Along with these two types of activities, we may have functions to retrieve the state of the application which may then be fed into an expected result calculation within a test we perform later in our scenarios.
The functions for retrieving application state are critical for automated testing. Consider a banking transaction: we would need to compare the previous balance of the account against the new balance to retrieve an expected result which we can use to assert our test is successful. Page objects facilitate this type of validation routine in an elegant way:

Figure 6: A page object created for a banking application retrieves information about
the application state that is critical for testing.
A collection of page objects for an application makes up a page object repository. A test script leverages the page object repository by creating an instance of each object, and making sequential calls to the required actions within the respective page objects in turn. Consider the following test which is a negative test for our login functionality. Here we are entering a username, entering a password, clicking login, and performing an assertion to ensure an error message appears: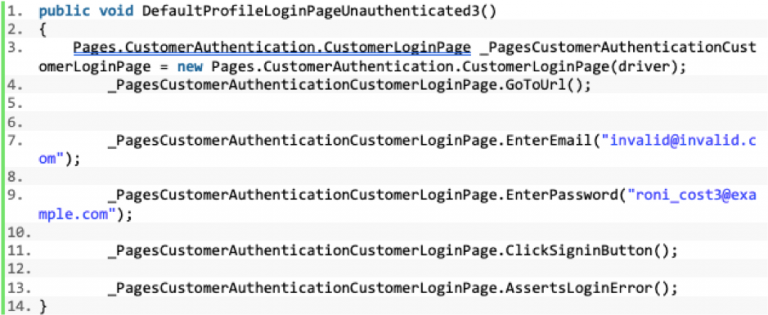
Figure 7: A negative test scripted using the page object model tests the validation of a logic screen
This example shows how the complexity of the underlying code and automation execution engine is abstracted from our test scenario and managed by the page object.
Page objects typically take two forms. Firstly, we have a specific page object which directly represents a piece of functionality in the application. This form reflects a one-to-one mapping of page object to application functionality. We can also have generic page objects which represent a generic piece of functionality in the application. These reflect one-to-many mapping.
Consider the following example. An e-commerce system may feature many products available for consumers to view and purchase. A trivial implementation would be a page object for each product available. This is a bad design choice.
A much better way to tackle this would be to create a generic page object which handles any product page within the e-commerce system. In our case, this is also synonymous with how the e-commerce system was implemented in development, where there is a generic page handling and rendering the products from the backend database.
By and large, this example shows the need to make pages objects as generic and reusable as possible, in order to avoid bloating the automation framework with unnecessary and essentially hard-coded, duplicated code. In the software development community, to the same extent, we follow the DRY principle: “Don’t Repeat Yourself.” Page objects should strive to be as minimal and reusable as possible.
Page objects are not just relevant to functional user interface testing, but also to other types of testing. In its rawest form, a page object is an interface between the test case and the underlying system under test. The page object could use any automation engine (like Selenium, Appium, or Winium), across any environment (desktop, web, mobile, or mainframe). The page object protects us and abstracts away from this implementation detail.
One instance where page objects can be applied is functional API testing, which by proxy can also be transposed to performance testing in which we’re performing an API test at volume. In this scenario, each page object represents an API endpoint. We can call that API endpoint with various messages and perform different methods like GET, POST, PUT, DELETE.
All of this is exposed within a class which can then be used to perform the requests through an API testing framework. In this case, we’re using REST Assured. The page object contains all the detail to fire the request and assert that the necessary states are returned, all of course abstracted through the page object:
Figure 8: An API test created using the Page Object Model for a REST Assured framework.
Like with our UI test scenarios, our tests leverage the page objects when defining tests, in turn calling the appropriate actions. In this case, we would perform our API requests and assert the responses. This is particularly useful when you consider end-to-end functional API tests, in which we need to chain together several requests with the responses fed into each other. This minimizes duplication and facilitates reuse across our test suite, while also being flexible to the API specification changing over time.
The page object model is a proven architecture in a world where complex apps require customized solutions. It is an essential design pattern for creating scalable and maintainable test automation frameworks which stand up to the pace of development faced by the introduction of agile methodologies. This is especially true page object model architecture is combined with page object scanners and recorders, capable of rapidly building page object libraries from existing applications.
The page object model, of course, only helps us with locator changes and does little in the way of assisting test maintenance for when the logical flow of the application changes. Test Modeller is a model-based testing tool which allows users to overlay their page objects onto a model and chain them together to create coverage focused tests. If the system flow changes, only the model needs updating, an approach to test automation that is demonstrated on Curiosity’s webinar: Model-Based Test Automation.

Banks globally rely on Oracle FLEXCUBE to provide their agile banking infrastructure, and more today are migrating to FLEXCUBE to retain a...

Each year, organisations and consumers globally depend on Oracle FLEXCUBE to process an estimated 26 Billion banking transactions [1]. For...

Any successful project relies on three core components. People and process, along with appropriate tooling to support these two in tandem. When these...

Despite increasing investment in test automation, many organisations today are yet to overcome the barrier to successful automated testing. In fact,...

This is Part 1/3 of “Introducing “Functional Performance Testing”, a series of articles considering how to test automatically across multi-tier...

Organisations today have long understood the need to automate test execution, and 90% believe that automated testing allows testers to perform their...

Continuous Integration (CI) and Continuous Delivery or Continuous Deployment (CD) pipelines have been largely adopted across the software development...

Data is the lifeblood of any modern organisation, the majority of which today use Business Intelligence tooling to inform critical decisions. ...

This is Part 3/3 of “Introducing “Functional Performance Testing”, a series of articles considering how to test automatically across multi-tier...