 Thomas Pryce
Thomas Pryce
Removing Quality Bottlenecks in CI/CD and DevOps
Curiosity often discuss barriers to “in-sprint testing”, focusing on techniques for reliably releasing fast-changing systems. These solutions...


![]() AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
![]() Test Case Design Generate the smallest set of test cases needed to test complex systems.
Test Case Design Generate the smallest set of test cases needed to test complex systems.
![]() Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
![]() API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
![]() Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
![]() Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
![]() Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
![]() Data Masking Identify and mask sensitive information across databases and files.
Data Masking Identify and mask sensitive information across databases and files.
![]() Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
![]() Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Help & Support Find a solution, request expert support and contact Curiosity.
Help & Support Find a solution, request expert support and contact Curiosity.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
![]() Integrations Explore Modeller's wide range of connections and integrations.
Integrations Explore Modeller's wide range of connections and integrations.
![]() Meet Our Team Meet our team of world leading experts in software quality and test data.
Meet Our Team Meet our team of world leading experts in software quality and test data.
![]() Our History Explore Curiosity's long history of creating market-defining solutions and success.
Our History Explore Curiosity's long history of creating market-defining solutions and success.
![]() Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
![]() Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
![]() Careers Join our growing team of industry veterans, experts, innovators and specialists.
Careers Join our growing team of industry veterans, experts, innovators and specialists.
![]() Press Releases Read the latest Curiosity news and company updates.
Press Releases Read the latest Curiosity news and company updates.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Contact Us Get in touch with a Curiosity expert or leave us a message.
Contact Us Get in touch with a Curiosity expert or leave us a message.

My two most recent blogs have made the case for a new TDM paradigm called “Test Data Automation”. The first article considered how a logistical approach to TDM (subset, mask, clone) undermines testing speed and quality. Last week considered the value of introducing synthetic test data generation from the perspective of compliance.
This week’s blog considers synthetic test data from the perspective of testing rigour. Next week will conclude the discussion by considering further how “Test Data Automation” also drives up testing agility. To discover how to implement this new TDM paradigm in practice, please join Curiosity’s Huw Price in the DevOps Bunker. On the webinar, Huw will make the case that “The Time for a New Test Data Paradigm is Now“.
In 2019, the fundamental approach to test data creation remains largely the same as it has been for decades. TDM “best practice” for most vendors and organisations amounts to moving copies of production data to test environments as quickly as possible. In fact, 65% of organizations use production data in testing. 36% mask it and 30% subset data before provisioning it to test environments [i].
Using production data in QA is itself always not a problem – the test data will often reflect complex system logic accurately and masking effectively can elevate compliance concerns. The challenge for testing rigour arises when QA teams depend on production data alone. This remains the case for many organisations, and only 18% synthesize data using automated techniques [ii].
The challenge to test quality is seen clearly by considering what production data copies do not contain. In terms of achieving full functional test coverage, test data must include:
Data for testing new or updated functionality. This is by definition missing from production data which is drawn from user behaviour exercised against a previously released system. Production data therefore lacks the data needed to test new functionality, and will be out-of-date for system logic that has been updated in the latest release. Imagine that a new field has been added to a web registration form: how can production data already contain this data, let alone the full spread of valid and invalid values required to rigorous test the form?
Outliers and edge cases: Production data is typically narrow and highly repetitious, focusing on expected user behaviour. Users almost always behave in the way the system intends, and do not therefore produce the data combinations needed to test outliers and edge cases. Production data therefore lacks the outliers and edge cases needed for sufficient test coverage.
Negative Scenarios: Production data copies for the same reason tend to be “happy path” in focus, lacking the data needed to test negative scenarios. However, it is these negative scenarios that cause the most severe defects. It is the role of QA to test against unexpected behaviour in advance of a release, for instance, testing error handling and data validation.
Figure 1 – Repetitious production data contains just a fraction of the combinations
needed for rigorous testing.
This low coverage allows defects to slip through QA, where they can impact user experience and a business’ bottom line. The time and expense required to fix the bugs is further driven up, and research has long-established that the effort of fixing defects increases the later they are detected in the software delivery lifecycle. To truly assure quality, a new approach to test data provisioning is required.
My blog last week set out how synthetic test data generation can help alleviate compliance concerns in testing. The same approach is capable of generating data combinations not found in production, enabling rigorous testing of fast-changing systems.
Last week’s blog also observed how organisations cannot swap all their copied data for synthetic data at once. Instead, a “hybrid approach” should be taken, strategically augmenting existing test data with rich synthetic test data. Some requirements for adopting this approach are set out below.
Generating complex data to test complex systems requires a flexible approach. The good news is, many of the skills and techniques required build naturally on effective masking and subsetting. All three tasks require a solid understanding of the relationships that exist in production data, and must reflect complex data models accurately. Synthetic test data generation is therefore not an impossible leap for organisations who currently mask and subset.
Some TDM tools additionally provide automated data modelling, further simplifying and accelerating the process of synthetic test data generation. With Curiosity’s Test Data Automation, this automated modelling identifies the trends in data that must be retained for testing, establishing the relationships within relational databases, files, and mainframe data sources. It builds the rules needed to retain referential integrity, including, for example, complex numerical and temporal patterns within data.
QA teams and DBAs then only need to provide definitions for the additional data variables required in testing, generating a coverage-optimised set of data that matches production data models accurately: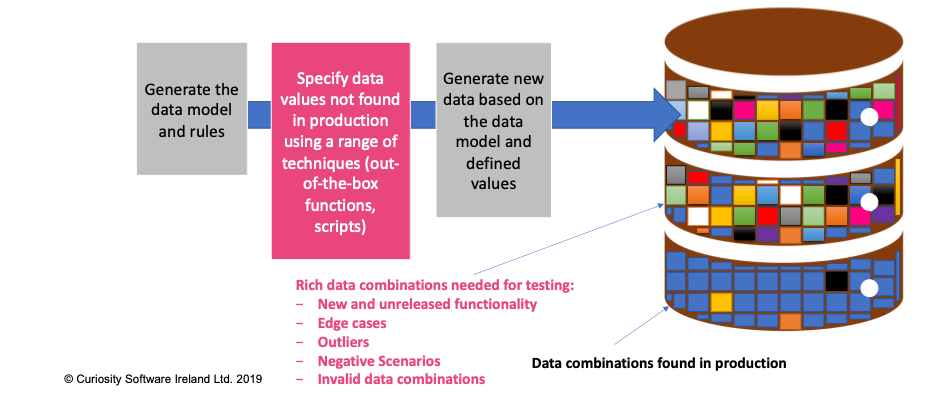
Figure 2 – Synthetic test data generation creates missing combinations needed for
rigorous testing.
Different techniques can be used in this “fill-in-the-blanks” approach to defining data combinations needed for rigorous QA. You can use scripting, while some tools provide data generation functions. The flexibility required to test complex applications requires a range of techniques, and some generation tools therefore provide a combination of methods when defining synthetic variables.
Generating data to test complex systems also requires a range of different techniques for creating the resultant data. These techniques include:
Direct to Databases: This generates data directly into relational databases.
Via the front-end: There is not always direct access to the back-end database, and sometimes it is simpler to push data through the front-end. This will reflect the data model in the back-end databases. When performed as a step during automated testing, it also prepares accurate data for testing on-the-fly.
Via the middle layer: Alternatively, you might want to leverage the API layer, inputting data via SOAP and REST calls.
Using files: Testing certain systems will require data to be sent via files, including XML, EDI and more.
Data for the mainframe: Mainframe data can be particularly difficult to create, and organisations still often laboriously input data via green screens. Tools like Ostia’s Portus create a transparency layer to a wide-range of mainframe data types, while data can also be sent in files via FTP or via REST Calls. Sometimes, it might be preferable to send data via generated scripts and files (XML, EDI, JCL, IDCAM, etc.).
Virtual data generation: This generates synthetic Request-Response pairs for service and message virtualisation. Generating accurate virtual data is useful for creating complete test environments when system components are missing or unavailable.
Finally, synthetic test data generation for complex systems must be able to reflect complex business logic and rules. The resultant data must reflect any instances where a prior event in the system influences subsequent events. For instance, if a value entered by a user on one screen is aggregated on a subsequent screen, this business rule must be reflected in the synthetic test data. Data generation must therefore include “event hooks” to define this chronology, and the rules should be easy to define.
Creating combinations of data not found in production is essential for rigorously testing complex and fast-changing systems. Creating this complex data requires a flexible approach. For organisations today, this might include one or all of the following characteristics:
Data generation should build on the skills already required for masking and subsetting, as many organisations already perform these processes;
Automated data modelling removes much of the complexity of defining generation rules for complex test data;
A combination of multiple techniques defining the data combinations needed by QA. This might include scripting and a combination of both out-of-the-box and custom expressions;
The methods for creating data based on the rules and definitions must also be flexible, for instance generating data directly to databases, or via the front-end, the middle layer, and files.
Data generation must also reflect business rules accurately, for instance using easy-to-define “Event Hooks”.
Synthetic test data generation can generate the negative scenarios and outliers needed to maximise test coverage. Generating the missing data combinations needed by testing can furthermore improve QA agility, the subject of next week’s blog. To learn more about test data generation and the latest trends in TDM, please watch Huw Price’s DevOps Bunker webinar on. During the live session, TDM veteran Huw will discuss why “The Time for a New Test Data Paradigm is Now“.

[i] Redgate (2019), State of Database DevOps, 23. Retrieved from http://assets.red-gate.com/solutions/database-devops/state-of-database-devops-2019.pdf on 19 June 2019.
[ii] Ibid.

Curiosity often discuss barriers to “in-sprint testing”, focusing on techniques for reliably releasing fast-changing systems. These solutions...

Throughout the development process, software applications undergo a variety of changes, from new functionality and code optimisation to the removal...
In the world of software development, generative AI has established itself as a formidable ally, assisting developers in coding and detecting...

Last week, we published a blog making the case for the next generation in TDM “best practice”. We considered why the logistical approach of “mask,...

In many large organizations, software quality is primarily viewed as the responsibility of the testing team. When bugs slip through to production, or...

Software delivery teams across the industry have embraced new(ish) approaches to development, from the different flavours of agile, to DevOps,...

Discover how Curiosity helps organisations delivery better quality software, faster. This infographic highlights key ways that Curiosity's tools,...

For many organisations, test data “best practices” start and end with compliance. This reflects a tendency to focus on the problem immediately in...

Today, there is a greater-than-ever need for parallelisation in testing and development. “Agile” and iterative delivery practices hinge on teams...