 Thomas Pryce
Thomas Pryce
Removing Barriers to In-Sprint Testing and Development - Infographic
Test automation must be lightweight, re-usable and easy to apply, in order to help organisations, ease its implementation enterprise wide. Curiosity...


![]() AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
![]() Test Case Design Generate the smallest set of test cases needed to test complex systems.
Test Case Design Generate the smallest set of test cases needed to test complex systems.
![]() Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
![]() API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
![]() Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
![]() Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
![]() Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
![]() Data Masking Identify and mask sensitive information across databases and files.
Data Masking Identify and mask sensitive information across databases and files.
![]() Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
![]() Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Help & Support Find a solution, request expert support and contact Curiosity.
Help & Support Find a solution, request expert support and contact Curiosity.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
![]() Integrations Explore Modeller's wide range of connections and integrations.
Integrations Explore Modeller's wide range of connections and integrations.
![]() Meet Our Team Meet our team of world leading experts in software quality and test data.
Meet Our Team Meet our team of world leading experts in software quality and test data.
![]() Our History Explore Curiosity's long history of creating market-defining solutions and success.
Our History Explore Curiosity's long history of creating market-defining solutions and success.
![]() Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
![]() Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
![]() Careers Join our growing team of industry veterans, experts, innovators and specialists.
Careers Join our growing team of industry veterans, experts, innovators and specialists.
![]() Press Releases Read the latest Curiosity news and company updates.
Press Releases Read the latest Curiosity news and company updates.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Contact Us Get in touch with a Curiosity expert or leave us a message.
Contact Us Get in touch with a Curiosity expert or leave us a message.

Curiosity often discuss barriers to “in-sprint testing”, focusing on techniques for reliably releasing fast-changing systems. These solutions accelerate and optimise processes that prevent organisations from making incremental improvements to complex systems.
Common barriers to in-sprint testing include flawed software design, slow test case creation, repetitive test scripting and time-consuming test data provisioning. You can see how Curiosity solve these challenges in our latest infographic, and on our next webinar: In-Sprint Testing: Aligning tests and teams to rapidly changing systems.

Curiosity recently received a great question from a senior tester: How do these testing accelerators further apply to CI/CD and DevOps?
The question hits on a key point for CI/CD and DevOps: how can testing processes match the speed and automation of CI/CD and DevOps pipelines, avoiding testing bottlenecks when making incremental changes to complex systems?
This article summaries three perennial blockers to CI/CD and DevOps, discussing how solutions for “in-sprint testing” can also unlock Continuous Testing and Delivery. It concludes with a nod towards Test Modeller, which leverages data analytics to make testing truly reactive to rapid change. This is because it makes testing proactive to rapid change.
The below processes are time-consuming testing activities that are unreactive to change, and which struggle to ensure the test coverage needed to release quality software reliably. Fortunately, automated solutions are available for each. These solutions can be integrated into CI/CD pipelines and DevOps toolchains, rapidly and reliably testing fast-changing systems after incremental changes.
This is a big blocker for CI/CD and DevOps, as often the manual processes involved in test data provisioning clash with the automation and evolution built into CI/CD. Automated tests and test teams are frequently held up by lengthy waits for manual data provisioning. Incomplete data further undermines test coverage, while inaccurate data and data clashes lead to time-consuming test failures.
Test Data Automation is a concept (and product) that aims to make all these TDM processes reusable and reactive, integrating them into test automation frameworks, DevOps pipelines and CI/CD infrastructure. That means that tests trigger automated data “find and makes” as they are generated and run, equipping every test with the complete and consistent data.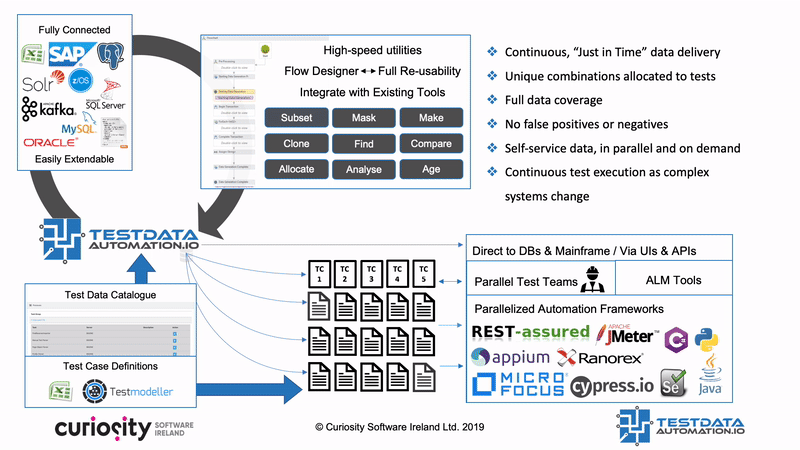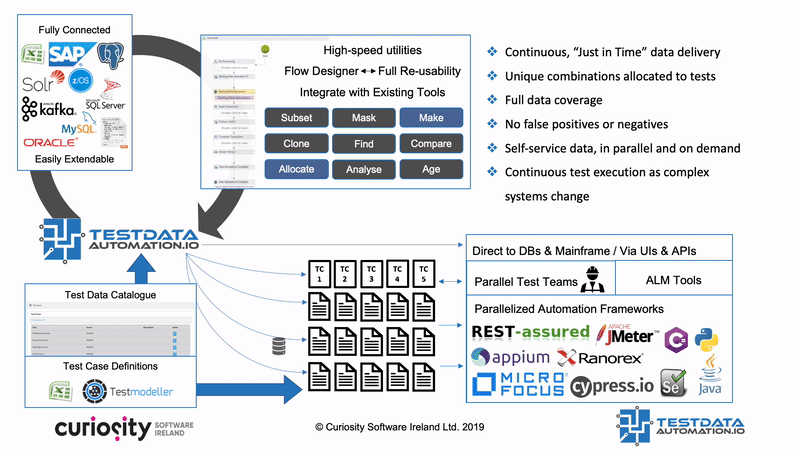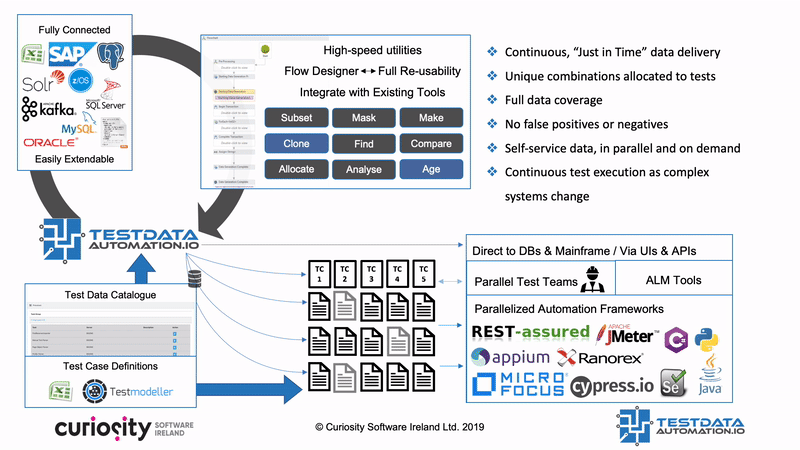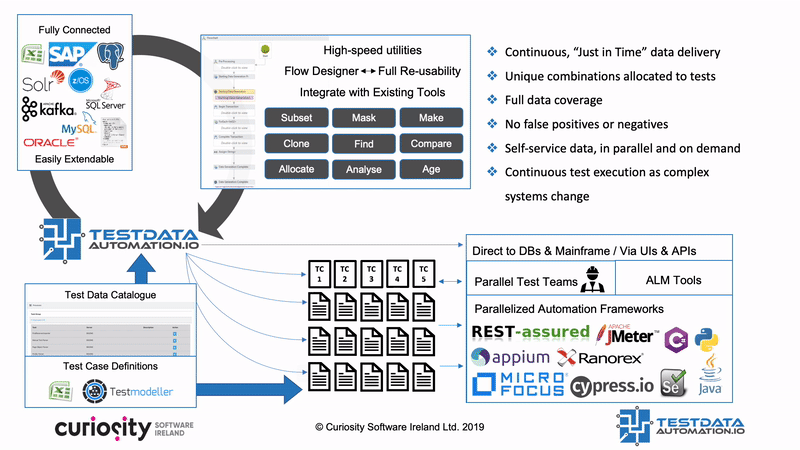 Test Data Automation furthermore integrates processes like masking and subsetting, right-sizing data and ensuring compliance. This self-provisioning of data in turn removes one of the greatest bottlenecks in testing, and so one of the greatest barriers to CI/CD and DevOps
Test Data Automation furthermore integrates processes like masking and subsetting, right-sizing data and ensuring compliance. This self-provisioning of data in turn removes one of the greatest bottlenecks in testing, and so one of the greatest barriers to CI/CD and DevOps
Curiosity’s most recent webinar, Data Breaks DevOps: Why you need automated test data in CI/CD, set out a strategy for allocating data on-the-fly within CI/CD pipelines.
Much of the same applies to test case creation and scripting. Today, both processes can be highly repetitive and time-consuming, while a lack of measurability means there is no guarantee of the coverage needed to deliver continuously and reliably.
Test Modeller auto-generates both test cases and scripts for a wide range of test case management tools and automation frameworks, using coverage algorithms to target testing where it’s needed in-sprint.
This automatically generates the smallest set of tests needed based on time and risk. Exposing the test generation to CI/CD tools and source control systems auto-generates the tests as part of CI/CD and DevOps pipelines. This replaces the time lost to repetitive and cumbersome test creation, enabling Continuous Testing and so Delivery.
You can see this automated and optimised approach to test creation live on Curiosity’s next webinar, In-Sprint Testing: Aligning tests and teams to rapidly changing systems.
3. Test Maintenance
Manual test scripting and data provisioning cause substantial bottlenecks in CI/CD and DevOps.
Manually created tests are usually brittle to change, while there is little traceability to source code or requirements. That means that there is little automation or no when identifying which tests need updating or removing.
Meanwhile, data must be refreshed, repeating many of the test data bottlenecks discussed above. Test cases, scripts and data are furthermore rarely linked to one another, or to requirements, and so all need checking and updating separately to keep them aligned.
The advantage of generating tests and allocating data automatically from intuitive flowcharts is that you only need to update one single source of truth. Making a relatively quick changes to a single flowchart will ripple across all interrelated master flows and “subflows”, regenerating an up-to-date set of test cases and scripts. Test data “find and makes” similarly become reactive to changes as the models are updated.
Automating test data allocation, test creation and maintenance accelerates and optimises testing processes often responsible for blockers during Continuous Delivery and DevOps. The automated processes can all furthermore be integrated with CI/CD infrastructure, rigorously and automatically testing fast-changing software with every rapid release.
This in-sprint testing becomes truly rapid and reactive when it is tied to Curiosity Test Modeller.
Test Modeller gathers and analyses data from across the whole application development lifecycle, seeking to expose significant changes as they occur. Exposing this data to a “model in the middle” then regenerates tests and data as changes occur:
Test Modeller thereby provides an “Early Warning System” for testing, informing testers of changes in source control systems, system requirements, user behaviours, and more. It furthermore analyses changes to identify risk, prioritising the tests that should be run during that sprint. In other words, it informs testers of changes that have occurred and helps them identify the tests required to act on that information.
The last component of this “Inform, Act, Automate” paradigm is then the automation needed to run the requisite tests. This goes beyond test execution automation, encompassing the solutions described above. Having identified the tests needed to act on the latest changes, automated test generation combines with test data allocation to create the requisite in-sprint tests.
Tying this automation together with CI/CD and DevOps infrastructure begins making this process continuous, especially when all are embedded within Test Modeller.
To return to the question driving this article, then: the role of automated test generation, data allocation and automated test maintenance go beyond “in-sprint testing”. They remove barriers to delivering rigorously tested software continuously, while also removing bottlenecks in DevOps pipelines.
Test Modeller makes testing truly reactive to rapid change. This is because it makes testing proactive to rapid change.

Test automation must be lightweight, re-usable and easy to apply, in order to help organisations, ease its implementation enterprise wide. Curiosity...

Welcome to part 4/5 of 5 Reasons to Model During QA! If you have missed any previous instalments, use the following links to see how modelling can:

Welcome to part 3/5 of 5 Reasons to Model During QA! Part one of this series discussed how modelling enables “shift left” QA, eradicating potentially...

Continuous Integration (CI) and Continuous Delivery or Continuous Deployment (CD) pipelines have been largely adopted across the software development...

For many organisations, test data “best practices” start and end with compliance. This reflects a tendency to focus on the problem immediately in...

Despite increasing investment in test automation, many organisations today are yet to overcome the barrier to successful automated testing. In fact,...

Application development and testing has been revolutionised in the past several years with artifact and package repositories, enabling delivery of...

At Curiosity, we talk about test data extensively, because we believe test data is repeatedly neglected in testing and development discussions....

Okay, so that title doesn’t make complete sense. However, if you read to the end of this article, all will become clear. I’m first going to discuss...