 Huw Price
Huw Price
Bringing Clarity to Complexity: Visual Models in Requirements Engineering
In the dynamic, interconnected world of software development, clarity is key. Yet, requirements engineering - the process of defining, documenting,...


![]() AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
![]() Test Case Design Generate the smallest set of test cases needed to test complex systems.
Test Case Design Generate the smallest set of test cases needed to test complex systems.
![]() Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
![]() API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
![]() Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
![]() Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
![]() Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
![]() Data Masking Identify and mask sensitive information across databases and files.
Data Masking Identify and mask sensitive information across databases and files.
![]() Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
![]() Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Help & Support Find a solution, request expert support and contact Curiosity.
Help & Support Find a solution, request expert support and contact Curiosity.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
![]() Integrations Explore Modeller's wide range of connections and integrations.
Integrations Explore Modeller's wide range of connections and integrations.
![]() Meet Our Team Meet our team of world leading experts in software quality and test data.
Meet Our Team Meet our team of world leading experts in software quality and test data.
![]() Our History Explore Curiosity's long history of creating market-defining solutions and success.
Our History Explore Curiosity's long history of creating market-defining solutions and success.
![]() Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
![]() Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
![]() Careers Join our growing team of industry veterans, experts, innovators and specialists.
Careers Join our growing team of industry veterans, experts, innovators and specialists.
![]() Press Releases Read the latest Curiosity news and company updates.
Press Releases Read the latest Curiosity news and company updates.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Contact Us Get in touch with a Curiosity expert or leave us a message.
Contact Us Get in touch with a Curiosity expert or leave us a message.

If you’re reading this, you’re likely already well aware of the value of watertight QA practice, and have good understanding of what it entails. Yet, there is possibly a team delivering business-critical software at your organisation who have thus far escaped the forensic focus of your testing. You need to talk to them, and this blog is a primer to help you do just that.
So, if you want to do one thing today to increase the measurable impact of QA at your organisation, do this: find out which team is developing your organisation’s search technologies and ask them how they’re testing them. There’s a fair chance that it’s a third-party search specialist, working with their own set of cutting-edge tools. In this case, verifying the quality of their testing practices becomes even more pertinent.
Search technologies today are delivered by the thriving and innovative search community, leveraging best-of-breed development methods like containerized deployment. They also build and use cutting edge open source technologies like Apache Lucene, Solr and Kafka.
The search engines this skilled community build are high visibility and high-impact, ranging from search engines on E-Commerce sites, to internal internets, content sharing platforms, and archives. In essence, any technology responsible for providing customers or employees with easy access to the information that organisations want them to see. For a sense of just how many organisations develop their own search technologies, see this list of organisations who use Solr to power their online search engines.
These search technologies are a pillar of smooth and satisfying user experience. They hold the keys to customer acquisition and retention, and therefore also to revenue. E-Commerce provides a clear example: if a user lands on a web store via Google, they are unlikely to trawl through the website for the items they want; however, they are likely to use the search engine to find the items they seek, as well as similar items recommended to them by relevant search results.
Search developers are expert in navigating this “Fuzzy Logic” of search relevancy, striving to make sure that users find satisfaction in their search engine and not a rival process or organisation.
Search engines clearly matter a lot; however, there is often a disconnect between this value and the techniques used to validate that search engines deliver the desired results. This creates a significant amount of negative risk: key components of business-critical, revenue driving systems are not being sufficiently tested and optimised.
That’s not to say that search specialists are not fine tuning their systems. They are, for example by validating search results manually with subject matter experts. There are also some great tools out there, like the open source Quepid.
The challenge is that search engine technologies contain a lot of logic that needs testing. The systems integrate and transform data from a wide-range of sources, producing results for an infinite set of possible terms.
This is a familiar challenge for QA: a vast web of interrelated components create a vast number of data journeys through the system logic. These journey must be tested using a comprehensive range of distinct data inputs to validate that the right output is produced.
Executing such a vast, complex set of data and measuring the results requires a systematic, scientific approach to testing. This science must encompass test case design, test data creation, and data-driven test execution. The volume of tests further requires a high degree of automation in creating and executing the tests, and that means that both expected and actual results must be formulated in a concrete, computer-readable format.
Today, search engine testing is frequently performed manually, but the sheer complexity of search engines means that manual testing alone cannot be relied upon to test their logic sufficiently during short iterations. Not only is the number of possible logical combinations too high, but there is simply no time to identify the tests and execute them manually. Rigorous functional testing instead requires automation, though there is still an important place for manual testing. For example, it’s good for exploratory testing, as well as smoke testing, verifying that code delivers some results. It’s also good for tuning as you code. However, it might not be capable of rigorous functional regression testing following each update made to a search engine.
This is not the fault of the search specialists. They are expert in the science of search and relevancy, and their time is focused to developing and focusing highly complex systems. They cannot be expected also to maintain comprehensive understanding of the equally complex and fast-evolving world of QA. This is where those of us in QA need to reach out and get stuck in, delivering valuable test results to search developers.
Search technologies therefore present a familiar problem for testers. That’s good news. It’s also a reason why QA should work more closely with search developers, introducing the science of cutting-edge testing to match the cutting-edge development techniques and tools used by the search community.
Further good news comes in the precise skills and knowledge already possessed by search engineers, many of which can be leveraged in QA. As mentioned, search technologies integrate and transform data from numerous sources. Search engineers are therefore adept, for example, in subsetting data and moving it between Solr cores and collections.
What’s missing is coverage-driven testing, and particularly automation in testing. For this, QA should collaborate with search experts to make explicit their subject matter expertise. They should work to understand and explicate the “Fuzzy Logic” of which searches are relevant, building tests on this understanding. By making this sometimes-subjective information concrete, testing can be automated. There’s also now some technologies to help with too.
I’ve dedicated much of my time recently to developing testing solutions for Apache Solr and Kafka, particularly automated solutions for data-driven search engine testing. These technologies focus on rapidly finding, securing and creating data, and firing it quickly into Solr and Kafka. The goal is to enable scientific, coverage-based test design, as well as the automation needed to quickly and repeatedly collect test results from evolving search technologies.
Combined with the extensive knowledge of search developers, the following technologies facilitate rapid and rigorous testing for Solr and Kafka.
Automated testing for search engines built on Solr and Kafka is data-driven, and efficient testing must be capable of feeding high volumes of data into test environments. Tests can then validate that the actual results match the well-formulated expected result for each test.
However, moving data into Solr and Kafka can be a complex procedure. The data must be drawn from the wide-ranging data sources that the search engine integrates and must be fed consistently into the containers used today to deploy search engine technologies.
To move data, search developers today frequently rely on a complex collection of SQL scripts, or use somewhat dated and now-unreliable technologies. For testers, these approaches are not only too slow, but they risk feeding in misaligned data. That data in turn undermines the reliability of test results, producing both false negatives and false positives.
This is why Curiosity have produced a high-speed utility for moving data into Solr and Kafka, providing a consistent and repeatable approach to data provisioning.
The automated data provisioning is parallelized to maximise performance. It splits the WHERE clauses used to move data, breaking data into chunks that can be moved in parallel. Last time I used it, the multi-threaded provisioning moved 231,000 rows of data in seconds and with a couple of clicks. The provisions can also be versioned by data source, providing the right configuration for the system under test.
The repeatable, standardized provisioning is furthermore exposed and made available to parallel test teams from an intuitive web portal. That means that QA no longer need to waste any time waiting for data provisioning. They can simply complete “fill-in-the-blank” style web forms to spin up Docker containers and move data in. Clicking “play” provides on tap access to data for testing systems built in Solr and Kafka: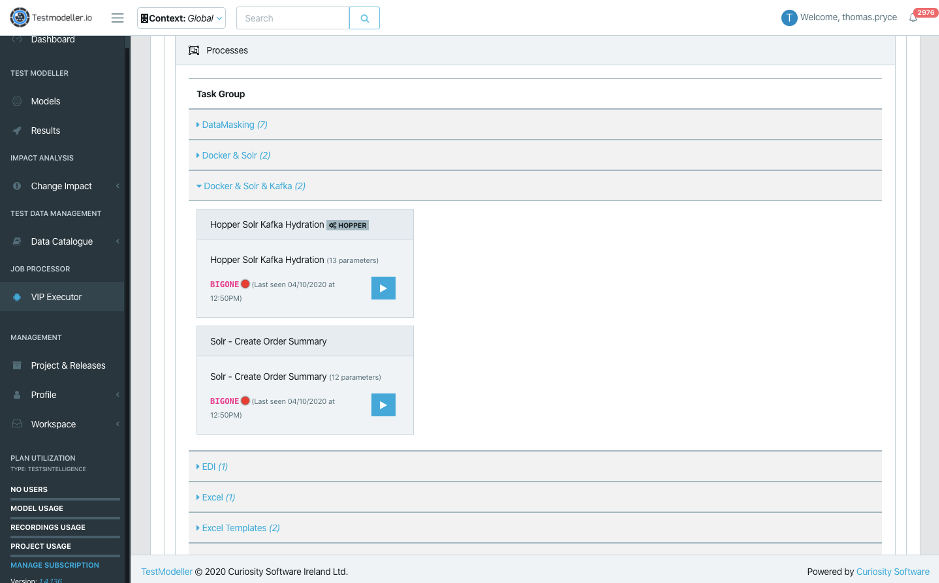
A self-service portal for provisioning data to Solr and Kafka.
Moving production data to less secure test and development environments presents a compliance risk, a subject that Curiosity have written about extensively. In the world of GDPR and CCPA that might apply to data generated by search technologies, which should be kept away from testing environments where possible.
One way to mitigate against the risk of a data breach and costly non-compliance is to anonymize data before its moved to test. However, this must not create a delay in data provisioning, while the masking must retain the referential integrity of data drawn from multiple sources.
This why Curiosity have integrated reliable data masking with Solr and Kafka data provisioning, securing data seamlessly as it moves to test environments. In this integrated approach, Data Protection Officers have peace of mind that sensitive information is being scrubbed before it reaches test environments. Meanwhile, testers still have on demand access to the data they need.
However, there are few circumstances where testers want or need a full set of production data in test environments. These large, repetitious data sets will typically run slowly and produce vast, hard-to-analyse results. Instead, testers require a data set to fulfil their exact test scenarios. Subsetting data on demand helps achieve just this.
Test Data Automation provides two types of subsetting which occur during Kafka or Solr data provisioning. “Criteria” subsetting extracts the data combinations needed to fulfil specific test scenarios, allowing testers to feed a controlled and compact data set into Solr and Kafka. They can then verify that a specific expected result has been achieved. A “Covered” subset is used when a maximally rich spread of test data is needed. These subsets combine the dimensions of existing data, in order to boast the number of scenarios exercised during test execution. They create richer test data on demand, enabling rapid and rigorous testing.
Both methods can occur as data is fed rapidly into Solr and Kafka. They are again available on demand, using the simple-to-use forms in Test Data Automation’s on demand execution portal: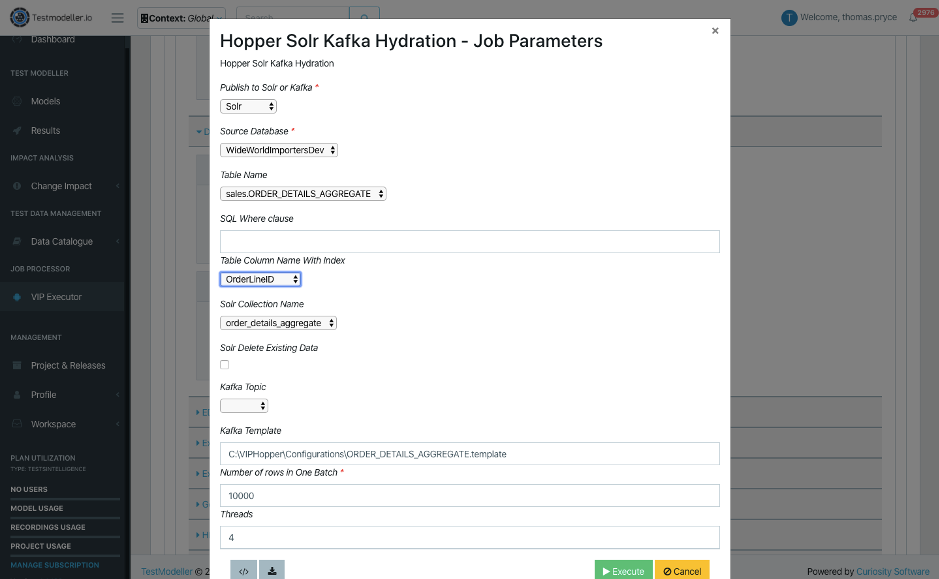
On demand data subsetting for Apache Solr or Kafka.
Another drawback of testing with production data that Curiosity has written extensively about is the quality of that data. Put simply, it lacks the values needed to rigorously test complex systems. This is particularly true for the outliers and unexpected results needed for rigorous negative testing. Even if you recombine the dimensions in historical production data, you will be left lacking. This is a problem that should be familiar to anyone who has done ETL or Business Intelligence testing using production data alone.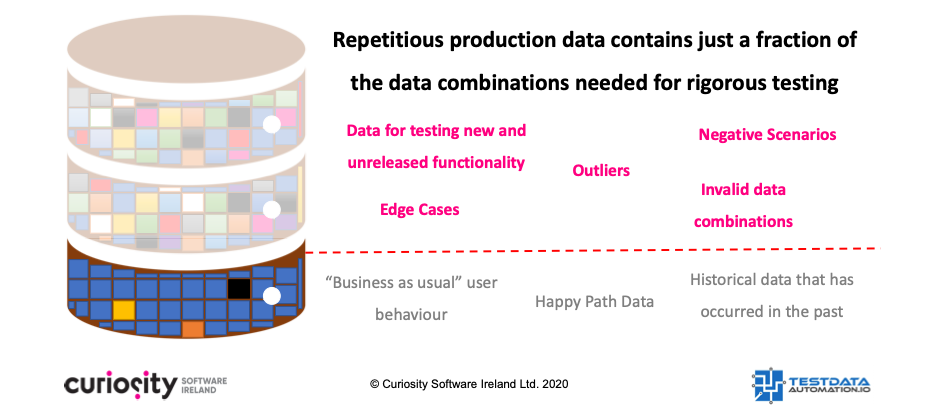
Production data lacks the majority of combinations needed to test Solr and Kafka rigorously.
Rigorously testing Solr and Kafka systems therefore requires data scenarios not found in production, ready to be pushed to test environments on demand. Curiosity’s automated approach to data provisioning therefore weaves in synthetic test data generation, augmenting data with missing combinations as it moves to test environments. This on demand approach performances data “Find and Makes” on demand. A “Find and Make” first searches in existing data sources for data to satisfy a given test suite, before making any missing combinations needed for the test suite.
This test data generation includes model-based test data generation, which is where search engine testing truly becomes the science discussed earlier. Model-based test generation builds a model of data journeys through a system, in turn finding and making the data needed to exercise a set of those journeys: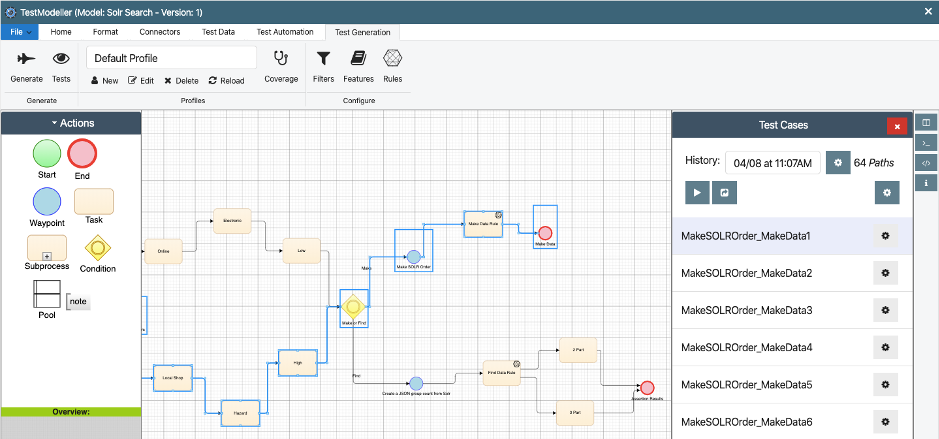
Model-based test generation for Solr.
The test generation applies powerful coverage algorithms, designed to identify the smallest number of “paths” through the model. The paths are equivalent to test cases, and test generation in turn creates the smallest set of tests needed to execute each logically distinct path through the model.
When testing Solr and Kafka, the distinction of test case and test data is blurred. The model-based testing therefore generates every logically distinct data journey through the model, creating a data set with which to test every distinct combination of equivalence class. It thereby introduces a rapid, repeatable and structured approach to test design.
The rigorous test generation leverages the power of computer processing to identify an executable number of tests for validating vastly complex data processing. The ability to combine modelled processes into master models makes rigorous integrated test design for Solr and Kafka possible, regardless of how many data sources are involved.
The sheer complexity of processing data from multiple, integrated sources makes Solr and Kafka testing perfect for integrated model-based testing and synthetic test generation. Multiple approaches are furthermore available in Test Modeller for integrating data generation with model-based test design:
The combination of model-based test design and test data automation creates a complete set of data journeys for rigorous test execution. These complete and readily executable data journeys are produced on demand, enabling complete and truly continuous test execution for search technologies built with Solr and Kafka.
As discussed at the start of this article, search engine development leverage best-of-breed technologies and development techniques like containerization. What’s missing is the science of testing to match the science of search. In particular, search development requires a structured approach to data-driven test design and execution.
The technologies set out in this article enable systematic and automated test data design of for Solr and Kafka. They furthermore provide the automation needed to fire them off to complex test environments on demand. This therefore provides a solid set of first moves when introducing test automation to search engine development.
I’m proud of what Curiosity have achieved so far with Solr and Kafka, and believe it fills a key gap at many organisations. My mind is now turning to consider techniques for defining sophisticated expected results for search engine testing. The end goal is to harness the “Fuzzy Logic” currently deployed by search engine developers when evaluating the quality of a searches, making these usable in automated tests.
This will likely involve capturing data from manual search testing, in turn explicating the criteria used to evaluate a given search. Analysing and making this data concrete will make these complex judgements usable in automated tests, facilitating sophisticated regression testing for search engines. The world’s our oyster here, with possibilities in machine learning, Expert Systems, and more.
If you’d like to get involved with this ongoing project, I’d love to hear your thoughts. Please also check out my demo video of the technologies discussed in this article.

Correction: This article was corrected on 3rd June 2020. An earlier version of this article contained the following paragraph:
“By this measure, the testing work performed by search developers is largely manual and unsystematic. It’s good for smoke testing and verifying that code delivers some results. It’s also good for tuning as you code. However, it’s not a science to match the science of search development. Nor is it capable of rigorously regression testing search engines each time something changes.”
We have revised this paragraph based on feedback which alerted us to the fact that the tone and meaning of the sentence did not accurately convey its intended meaning. The paragraph has been replaced with the following:
“Today, search engine testing is frequently performed manually, but the sheer complexity of search engines means that manual testing alone cannot be relied upon to test their logic sufficiently during short iterations. Not only is the number of possible logical combinations too high, but there is simply no time to identify the tests and execute them manually. Rigorous functional testing instead requires automation, though there is still an important place for manual testing. For example, it’s good for exploratory testing, as well as smoke testing, verifying that code delivers some results. It’s also good for tuning as you code. However, it might not be capable of rigorous functional regression testing following each update made to a search engine.

In the dynamic, interconnected world of software development, clarity is key. Yet, requirements engineering - the process of defining, documenting,...

The project, shortlisted for the "Best Use of Technology in a Project", reduced the time needed to create and run automated tests from weeks to...

APIs provide business with the flexibility to innovate rapidly and extend their core offerings to new users. However, this flexibility brings massive...

Welcome to part 3/5 of 5 Reasons to Model During QA! Part one of this series discussed how modelling enables “shift left” QA, eradicating potentially...
Welcome to part 2/5 of 5 Reasons to Model During QA! Part one of this series discussed how formal modelling enables “shift left” QA. It discussed how...

Model-Based Testing (MBT) itself is not new, but Model-Based Test Automation is experiencing a resurgence in adoption. Model-Based Testing is the...

The landscape of artificial intelligence is rapidly evolving. The recent announcement of GPT-4 with vision capabilities by OpenAI stands as a...

Software delivery teams across the industry have embraced agile delivery methods in order to promote collaboration between teams and deliver new...

Welcome to part 4/5 of 5 Reasons to Model During QA! If you have missed any previous instalments, use the following links to see how modelling can: