 Thomas Pryce
Thomas Pryce
Time to migrate from your legacy test data (TDM) tools? Here’s how.
If you’re reading this, you’re probably already painfully familiar with the complaints that Curiosity hear from organisations seeking alternatives to...



![]() AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
![]() Test Case Design Generate the smallest set of test cases needed to test complex systems.
Test Case Design Generate the smallest set of test cases needed to test complex systems.
![]() Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
![]() API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
![]() Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
![]() Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
![]() Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
![]() Data Masking Identify and mask sensitive information across databases and files.
Data Masking Identify and mask sensitive information across databases and files.
![]() Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
![]() Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Help & Support Find a solution, request expert support and contact Curiosity.
Help & Support Find a solution, request expert support and contact Curiosity.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
![]() Integrations Explore Modeller's wide range of connections and integrations.
Integrations Explore Modeller's wide range of connections and integrations.
![]() Meet Our Team Meet our team of world leading experts in software quality and test data.
Meet Our Team Meet our team of world leading experts in software quality and test data.
![]() Our History Explore Curiosity's long history of creating market-defining solutions and success.
Our History Explore Curiosity's long history of creating market-defining solutions and success.
![]() Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
![]() Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
![]() Careers Join our growing team of industry veterans, experts, innovators and specialists.
Careers Join our growing team of industry veterans, experts, innovators and specialists.
![]() Press Releases Read the latest Curiosity news and company updates.
Press Releases Read the latest Curiosity news and company updates.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Contact Us Get in touch with a Curiosity expert or leave us a message.
Contact Us Get in touch with a Curiosity expert or leave us a message.

Welcome to part 4/4 of this article series discussing the new paradigm in Test Data Management: “Test Data Automation”.
The drawbacks of traditional approaches to TDM were set out in Part One in this series. Logistical approaches to TDM focus almost exclusively on moving data as quickly as possible to QA environments, and TDM “best practice” amounts to “subset, mask, copy”. Part Two discussed the pitfalls of this approach from a compliance perspective, and Part Three then discussed why production data alone cannot drive testing rigour.
Both previous articles in turn outlined how synthetic data generation can support compliance and also provide the rich variety of data needed to test fast-changing systems. This final article considers “Test Data Automation” in terms of a third imperative of modern QA: testing at the speed with which modern applications change.
To discover more about the need for “Test Data Automation” and the technologies used in its implementation, please watch Huw Price’s live webinar in the DevOps Bunker. During the session, Huw will set out why “The Time for a New Test Data Paradigm is Now“.

“Logistical” approaches to TDM focus on moving production data to test environment as quickly as possible. The copies must be made at the speed with which production data evolves and must therefore must keep up with the release cadence for the systems under test.
Today, test Data provisioning must furthermore provide copies at the speed with which parallel test teams and their data hungry automation frameworks consume them.
Put simply, the siloed approach of “subset, mask, copy” cannot match this speed. TDM at many organisations is instead stuttered, provisioning a limited number of out-of-date copies. The individual TDM processes are frequently overly manual, hard to repeat, and inherently complex, and are therefore too labour-intensive and time-consuming.
Even with supporting technologies, masking, subsetting and copying large sets of production data is massively complex. Each TDM process must execute rules that retain the relationships within and across tables, as well as across whole schemas, databases, mainframe systems and files.
The relationships themselves are often highly intricate. An ECommerce System, for instance, might be built on a database where a column in one table feeds an aggregate in another. That aggregate might in turn feed a separate database underpinning an organisation’s Customer Relationship Management (CRM) system: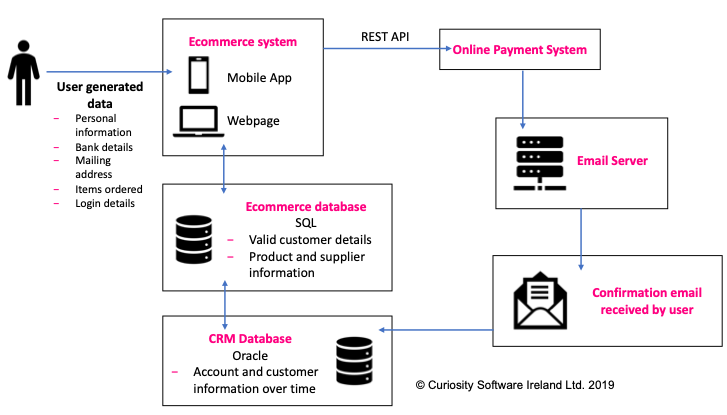
Figure 1 – Numerous data interrelationships exist in even a simplified Ecommerce system
Executing any one end-to-end test requires masked data that reflects this logical trend, in addition to all other relationships across the interdependent components. If the data used by any two parts of system during testing do not align, the tests will fail due to poor data, rather than due to defects in the code.
The relationships get more complex yet, for instance when temporal trends are required in test data. Testing a finance system, for instance, might require bank log files, and these log files will reflect transaction data over time. The individual values will feed aggregates over time, that must likewise be reflected consistently in anonymised test data.
Editing any production data must reflect each and every one of these relationships, and this is where delays typically arise test data provisioning. Masking might remove personally identifiable information in one place, but that data must be removed consistently, across all interrelated values. Subsetting likewise cannot remove any one value or row without consistently removing all interdependent data, as otherwise it creates an incomplete data set.
This complexity means that data copies are often out-of-date by the time they are created, and are therefore misaligned to the test cases that need executing. Errors also arise when formulating the immensely complex rules manually, creating inconsistent data that undermines the reliability of test execution.
A lack of re-usability means that the Ops team responsible for the data provisioning must furthermore repeat slight variations of the same process each time they provision data. This lack of automation in a siloed approach creates significant wait times for data, and the time spent waiting for data copies can sometimes be longer than the allocated time for an iteration.
In sum, this siloed approach to data provisioning leads to inaccurate testing, performed late, producing false positives and test failures when there are no genuine defects: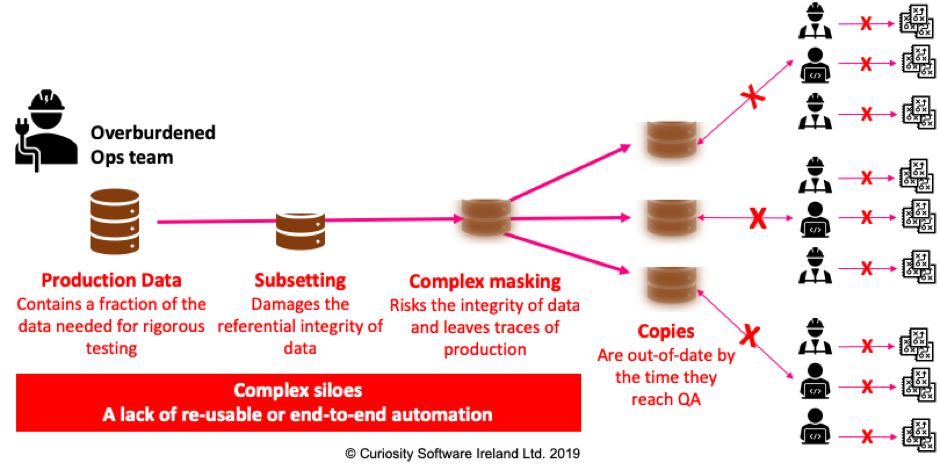
Figure 2 – A siloed approach delivers always-out-of-date copies of production data.
In addition to being out-of-date, the siloed approach can never provision enough copies of data quickly enough for parallelised test teams and data intensive test automation frameworks. An over-burdened Ops team instead typically provisions a limited number of copies, which parallel teams and automation frameworks must then compete for.
Numerous delays then arise as QA teams compete among large and unwieldy data sets: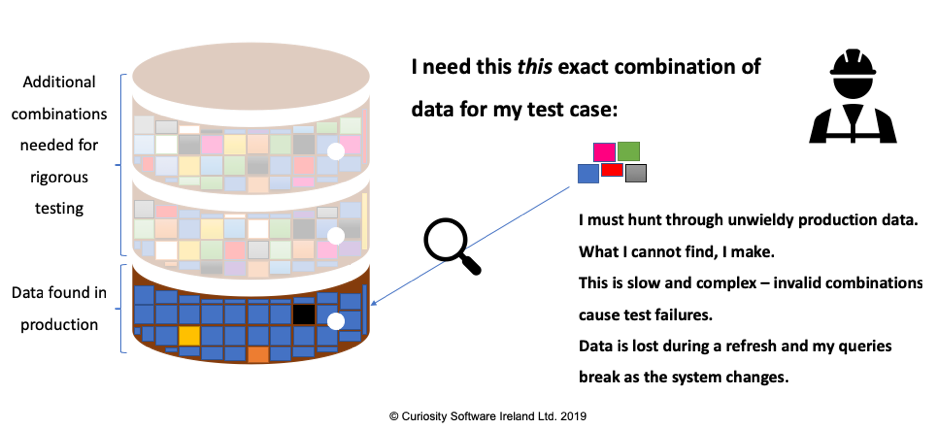
Figure 3 – Working with a limited number of unwieldy data sets further undermines
testing agility.
These delays associated with data provisioning force QA further and further behind rapid release cycles, with untested logic increasingly released to production. Rigorously testing fast-changing systems in short iterations instead requires an automated, self-service and on demand approach, moving from data “provisioning” to test-driven test data allocation and “preparation”.
The good news is that TDM processes that retain the referential integrity of data are inherently rule-based. They can therefore be automated and made repeatable. Embedding the automation within automated test execution and CI/CD pipelines in turn leads to automated and test-driven “Test Data Preparation”, a process that finds, makes, and prepares unique data combinations as individual tests are created or executed.
This removes the delays associated with cross-team constraints and inaccurate data, automatically finding and making data for individual tests. Building a self-service portal on top of the repeatable processes furthermore removes the reliance on an upstream team, while the Ops team can focus on creating new TDM processes to create data repeatable processes for fast-changing systems.
In this approach, the rules used to drive TDM processes must be formulated in a way that is repeatable. The definition of the rules must furthermore be flexible enough to work with variations in data, creating rich and realistic data as systems change. The re-usable rules must then be easily parameterizable, to avoid reworking and recreating processes as test data sources rapidly produce new data.
Defining rules in logical workflows provides one method for maximising re-usability. The workflow does not require constant maintenance or rework each time the TDM utility is run against a new data set. Instead, the decision gates in the flow handle the variation. This can be seen in the below flow used in synthetic test data generation, in which several processes contain are “nested” and handle the decision making:
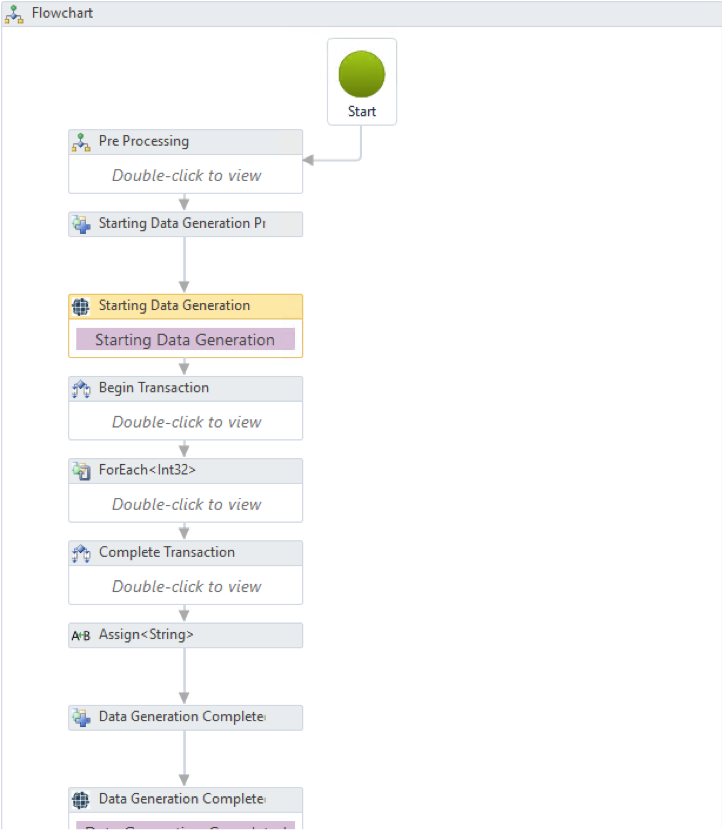
Figure 4 – Synthetic test data generation defined as a flexible and re-usable workflow, in which several subprocesses contain decision logic.
A human responsible for provisioning test data only needs to define the complex decision-making process once in a visual model, and everyone can then set parameters each time they re-use the process against a new data set.
The example flow above furthermore is taken from Curiosity’s Test Data Automation, which furthermore auto-generates a data model and populates many of the rules involved in test data management. This further removes the complexity from rule definition, retaining the integrity of complex data.
When testing complex systems, the workflow engine should furthermore be extensible, for example using APIs. Existing TDM processes and tooling can then also be incorporated in the re-usable TDM processes.
Building a self-service portal for repeating the TDM processes furthermore empowers parallel test teams to prepare the data they need, as they need it. The below example is taken from Test Modeller, and shows a simple UI for re-using processes stored in a “test data catalogue”: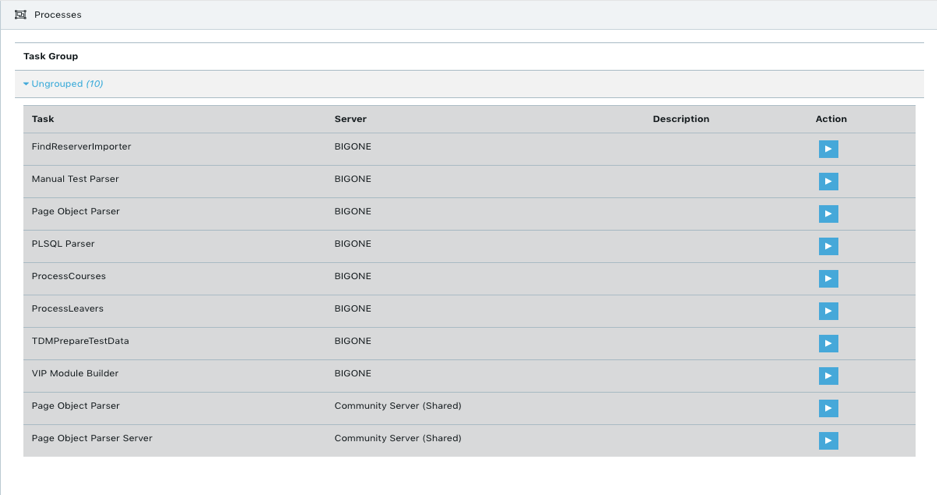
Figure 5 – A library of re-usable processes included the TDM tasks traditionally
associated with manual data provisioning.
In this approach, parallel testers are no longer dependent in this approach on an upstream team, but can select parameters in a simple form and hit “Play”. This will find, make and prepare the data they need, for instance subsetting data from a back-end database.
There are furthermore multiple methods in which the automated processes might be embedded within test automation and CI/CD pipelines, creating automated data “preparation”. Scripting or the command line might be used to invoke the process, as might integrated Continuous Integration engines.
Model-based Test generation provides another way to integrate data preparation within test automation, with the benefit that data can also be prepared as tests are generated. This approach embeds the re-usable TDM process as a node in the model, and test data preparation is then generated as a test step.
This is seen in the below example, in which a simple set of test cases are auto-generated from a model. The model includes a re-usable TDM process. As the tests are generated and executed, the re-usable process finds and makes data from a back-end database. Notice that each test has passed and valid data has been found for each, indicating that the pass result is not a false positive: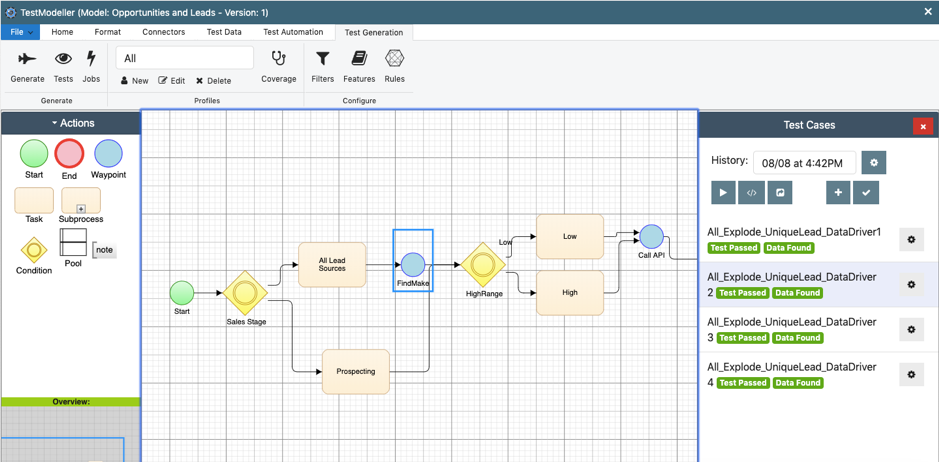
Figure 6 – Test cases generated from a model display that data has been found for
each test.
Preparing data for complex systems is typically a multi-step process, as seen currently when Ops teams run several processes against a database to create test data. An automated approach must therefore be capable of linking several repeatable processes together, while retaining the integrity of the data.
One workflow might perform this multi-step creation, as in the above example where data is both found and made. Alternatively, several automated processes might be chained together, passing values and parameters from one path to the step.
Multi-step preparation gathers disparate TDM technologies and processes into a unified approach. Embedding this “just in time” test data allocation as a standard step within test automation and CI/CD pipelines removes many of the bottlenecks discussed earlier. Several automated actions might typically then occur at the point of test execution:
Preparing data “just in time” during test creation and execution matches unique data combinations to each and every test. If multiple tests require similar data, unique identifiers are edited each time, all while retaining data integrity.
This ensures the validity of data for each and every test. In the above example, the automation furthermore validates the data “match” based on the test case definition. The definition is stored in the model, but the extendable workflows might also interact with test cases stored in spreadsheets, in test management tools, or beyond: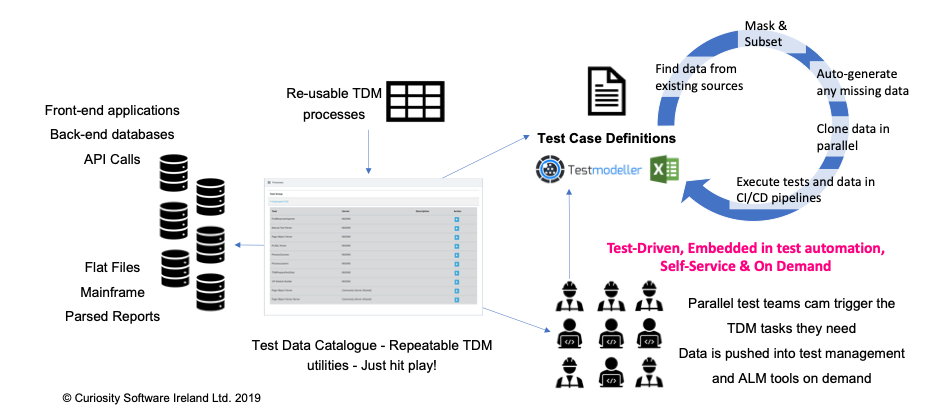
Figure 7 – Test Data Allocation continuously delivers up-to-date test data based on
the latest test definitions.
This process therefore ensures that each and every test has the data it needs, exactly when it is needed to test fast-changing applications. The constant availability of quality data in turn enables the continuous delivery of rigorously tested software, meeting the challenges of rapid software delivery.
To discover how Test Data Automation can align your test automation and data, watch Huw Prices’ live webinar, “The Time for a New Test Data Paradigm is Now“.

If you’re reading this, you’re probably already painfully familiar with the complaints that Curiosity hear from organisations seeking alternatives to...

Today, there is a greater-than-ever need for parallelisation in testing and development. “Agile” and iterative delivery practices hinge on teams...

Last week, we published a blog making the case for the next generation in TDM “best practice”. We considered why the logistical approach of “mask,...

A glance at industry research from recent years shows that test data remains one of the major bottlenecks to fix in DevOps and CI/CD:

For many organisations, test data “best practices” start and end with compliance. This reflects a tendency to focus on the problem immediately in...

Curiosity Software Ireland, creators of Test Data Automation, and Windocks, on demand database specialists, today announced a joint solution for...

In 2023, (test) data availability, quality, and compliance risks remain a major headache for software development.

Ever-tighter data privacy legislation like the EU General Data Protection Regulation and The California Consumer Privacy Act has made test data a...

My two most recent blogs have made the case for a new TDM paradigm called “Test Data Automation”. The first article considered how a logistical...