


 Test Data Subsetting
Test Data Subsetting
Referential Intact Data,
in Parallel and On Demand!


A Fortune 100 Financial Services Company

Reduced the time needed to provision data from 1+ days, to on demand provisioning.
A Global 2000 Financial Services Company
Moved from 1-5 days to fulfil data requests to self-service, automated provisioning.
A Top 10
Central Bank
Reduced data provisioning costs by 70% and maintained data 1400x faster.

Smaller Test Data Sets.
Minimise Infrastructure Costs.
Iterative data subsetting “crawls” across source data, collecting just enough data needed to retain relationships and variety. Testing with compact, virtualised subsets avoids the prohibitive storage costs associated with copying large production data sets to test.
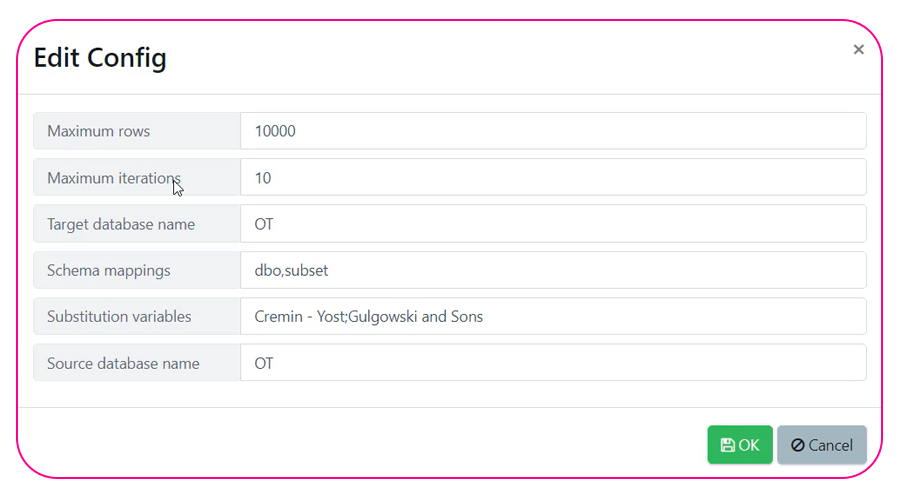
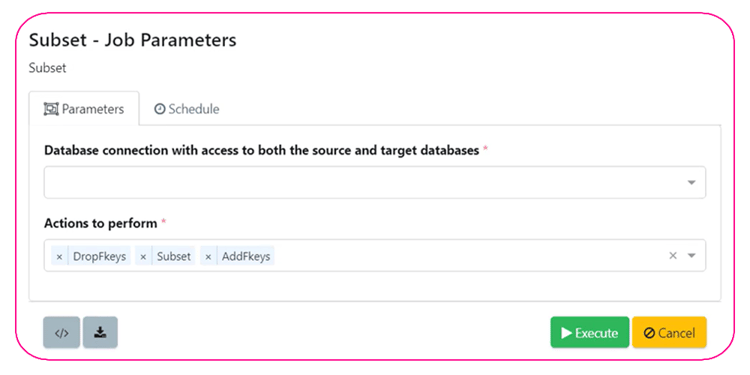
On Demand Data.
Shorten Release Cycles.
Self-service forms and on demand subsets provide data to testers, developers and CI/CD tools. Teams and tools test and develop in parallel, free from provisioning delays and data clashes. Self-serving rightsized data further avoids time lost finding data in large copies.
Optimal Test Coverage.
Test Rigorously with Fewer Tests.
Testing with concise data sets shortens test runs and creates fewer run results to analyse. “Criteria”, “Covered” and “Scenario” subsets produce the smallest data set needed to retain the variety of production or fulfil user stories and tests, rigorously testing to find bugs earlier.
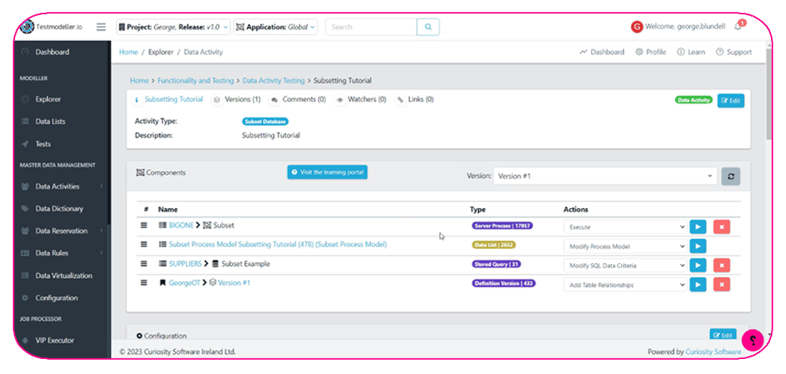




High-Performance Subsetting
Cascade joins, multi-threading, load balancing and parallel processing rapidly subset the volumes of data you need.
Quick and Easy Set-Up
Automatically identify relationships to fulfil during subsetting, picking from suggested rules in Test Data Automation’s intuitive web portal.
Referential Integrity
Subsetting “crawls” up and down parent and child tables, recursively gathering the related data needed in a coherent data set.


.png?width=120&height=120&name=noun-sql-file-237080%20(1).png)











