

Test Data Automation and Windocks
Complete and compliant data, pushed to containers in seconds
Test Data Automation and Windocks combine to provide complete and compliant data for testing complex systems in-sprint. The versioned data sets are virtualised and cloned to containers in seconds, leveraging high-speed generation, masking and subsetting to test rigorously in short iterations.

Test data “provisioning” has fallen behind modern development
Traditional test data management cannot keep pace with development today, forcing testing ever-further behind releases. Developers now leverage APIs, code libraries and containers to rip-and-replace re-usable components. DevOps-ready test data solution must provide versioned and interrelated data for these intricate mixes of technologies. Manually copying data to test environments is simply too slow and requires prohibitively costly infrastructure. The historic production data further lacks the diverse data needed for rigorous testing, leaving production systems exposed. To test rigorously in-sprint, test data must also embrace containerisation, automated deployment and “the world of the API”.

DevOps-ready data: Complete, compliant and on demand
Test Data Automation and Windocks combine to provide complete, compliant and on demand data for testing fast-changing system components. Windocks virtualises and clones data in seconds, minimising infrastructure costs and provisioning time as data moves on demand to containers. Test Data Automation masks, subsets and synthetically augments the data as it is containerised on demand, ensuring that parallel teams and automation frameworks have the rich data they need to test in-sprint. Testers and developers can work seamlessly from isolated, containerised data sets, quickly ripping-and-replacing the data sets they need to deliver quality software in short sprints.
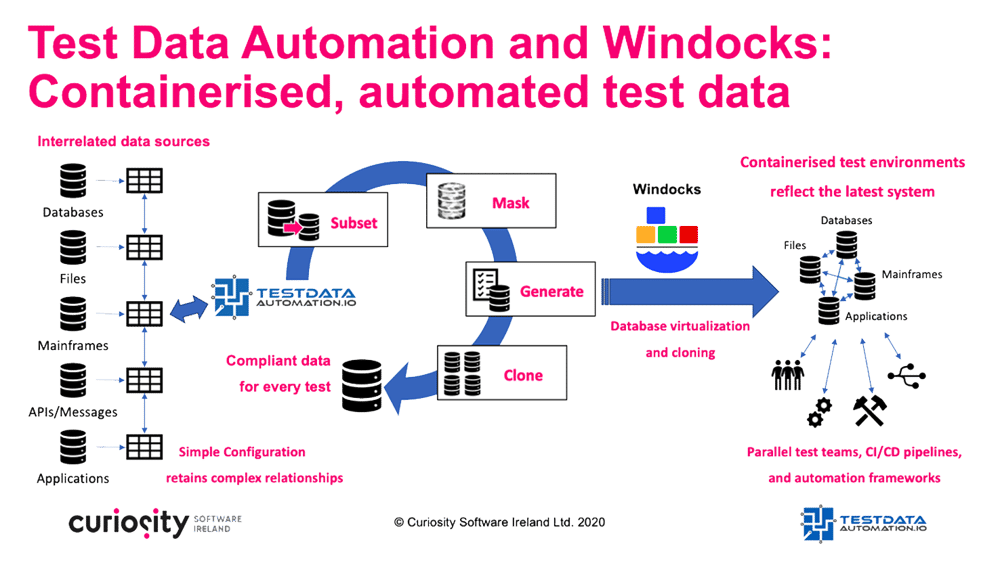
Both Windocks and Test Data Automation provide intuitive web portals, allowing testers and developers to spin up the containerised data they need on demand. Adding data generation, masking and subsetting is as quick and simple as filling in fields in customisable web forms, spinning up the exact data sets required for rapid and rigorous testing. The rapid and re-usable test data jobs can further be exposed to CI/CD pipelines and test automation frameworks, resolving on-the-fly as tests are created and run. This ensures that every test, tester and developer has the exact data combinations they need, exactly when and where they need them, delivering quality software in short iterations.

Speak with an expert
Discover how Curiosity can help you automate your test data management!