 Thomas Pryce
Thomas Pryce
Models in testing: Where’s their value?
System models: there’s lots of different techniques today, but where is their true value for testers and developers? Here’s five ways that I’ve found...


![]() AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
![]() Test Case Design Generate the smallest set of test cases needed to test complex systems.
Test Case Design Generate the smallest set of test cases needed to test complex systems.
![]() Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
![]() API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
![]() Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
![]() Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
![]() Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
![]() Data Masking Identify and mask sensitive information across databases and files.
Data Masking Identify and mask sensitive information across databases and files.
![]() Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
![]() Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Help & Support Find a solution, request expert support and contact Curiosity.
Help & Support Find a solution, request expert support and contact Curiosity.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
![]() Integrations Explore Modeller's wide range of connections and integrations.
Integrations Explore Modeller's wide range of connections and integrations.
![]() Meet Our Team Meet our team of world leading experts in software quality and test data.
Meet Our Team Meet our team of world leading experts in software quality and test data.
![]() Our History Explore Curiosity's long history of creating market-defining solutions and success.
Our History Explore Curiosity's long history of creating market-defining solutions and success.
![]() Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
![]() Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
![]() Careers Join our growing team of industry veterans, experts, innovators and specialists.
Careers Join our growing team of industry veterans, experts, innovators and specialists.
![]() Press Releases Read the latest Curiosity news and company updates.
Press Releases Read the latest Curiosity news and company updates.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Contact Us Get in touch with a Curiosity expert or leave us a message.
Contact Us Get in touch with a Curiosity expert or leave us a message.

Welcome to part two in this article exploring the benefits of model-based test design and maintenance for OpenText (Micro Focus) UFT. If you missed part one, go back to see how modelling can:
Read on to see how model-based testing tackles two further barriers to automation speed and rigour: the availability of accurate test data, and the time spent on manual test maintenance.
This article will then move from processes and technology, considering how modelling also benefits people, including testers, developers, and business stakeholders. It will set out how modelling provides a central point of communication, maximises re-usability and sharing of work, and works to eradicate the majority of bugs that stem from requirements.
If you would like to see any these benefits in action, please register for the on demand Vivit Webinar, Model-Based Testing for UFT One and UFT Developer: Optimized Test Script Generation.
Automated testing is only as rigorous as the data used during execution and is only as fast as the allocation of that data. It is unsurprising then that data remains one of the greatest barriers to test automation adoption, and more generally to testing in short iterations.
In fact, 56% of respondents to the last World Quality Report cite a lack of appropriate environments and data as a challenge when applying testing to agile environment, while 48% cite “Test Data Environment availability and stability” as a factor preventing their desired level of test automation.
48% of respondents to the last World Quality Report cite “Test Data Environment availability and stability” as a factor preventing their desired level of test automation.
The first challenge posed by data to test automation is the quality of the data, which must reflect the sheer variety of combinations needed to test today’s systems rigorously. Achieving sufficient test coverage requires data to hit every distinct positive and negative scenario, including outliers, unexpected results, and data needed for unreleased functionality.
This data is rarely found in the production data that, according to the World Quality Report, the majority of organisations still rely on in test environments. This data is drawn from past production usage and therefore cannot contain data for new functionality, while the repetitious data reflects the expected, “happy path” behaviour exercised by users: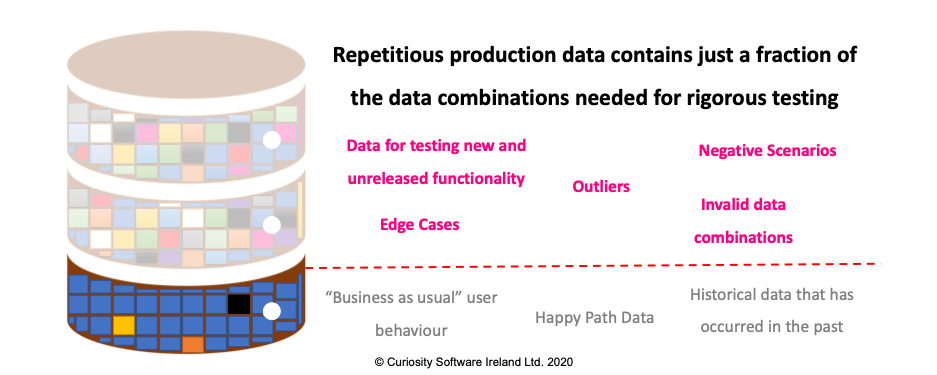
Figure 1 – Production data contains just a fraction of the data combinations needed for
sufficient test coverage.
In a nutshell, rigorous automated tests need to behave far more erratically than production users, but lack the data to do so, leaving complex systems exposed to damaging bugs.
The second challenge posed by data to automation is speed. Data provisioning methods remain manual, and cannot therefore match the speed of parallelised, automated test execution.
Data refreshes can take days or weeks, as a central team slowly copy and prepare production data from a range of interrelated data sources. QA teams then have to hunt through the unwieldy data sets looking for the exact combinations, while making complex and linked-up data combinations slowly by hand.
More time is lost due to inconsistencies in data sets that must traverse numerous components, but which do not reflect the relationships that exist across those components. Automated tests fail due to invalid, inconsistent, or out-of-date test data. Meanwhile, competition for a limited number of data sets creates delays among testers, while data-driven tests consume each other’s data during execution, leading to false negatives.
Model-based test generation for UFT provides an approach for generating data at the same time as tests, removing the bottlenecks associated with test data. This “just in time” approach assigns accurate and unique combinations for every script, working from the test definitions to ensure that data is valid and up-to-date.
One approach to “just in time” data allocation generates data from functions defined at the model level. Static data values or dynamic functions are assigned to each block or test step, and the automated test creation then resolves the functions and embeds the data values in the scripts themselves: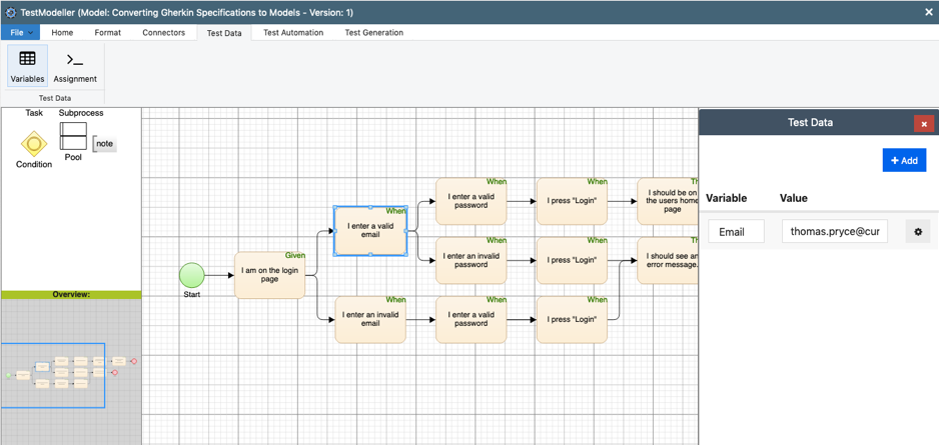
Figure 2 – Assigning test data functions or values to flowchart models.
Dynamic data definition assigns synthetic test data functions to each block, and the functions then resolve either when the tests are generated or dynamically during execution. This produces a wide-range of production-like values which link consistently across the whole test.
In Test Modeller, data not found in production is easily defined using over 500 combinable functions, ensuring that each and every UFT test comes equipped with the data needed for sufficient test coverage: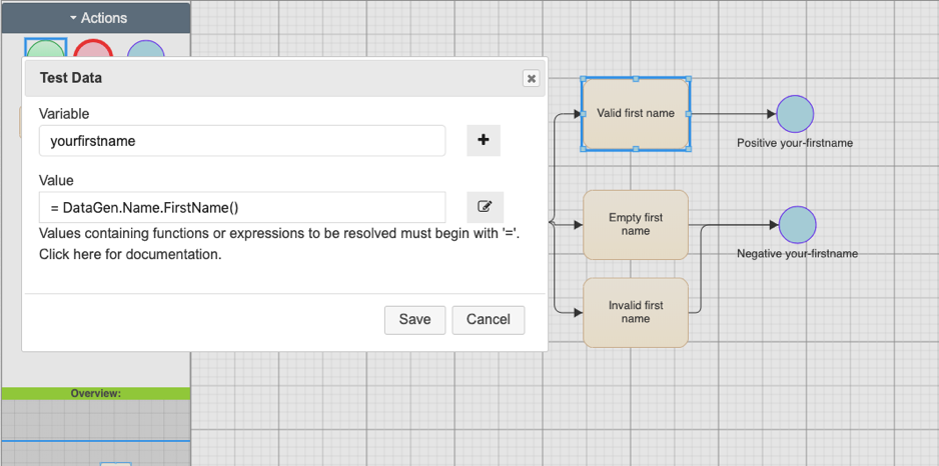
Figure 3 – Assigning synthetic test data functions at the model level. The dynamic
functions resolve “just in time” as tests are created or run, generating data for each test.
Another approach to data allocation embeds re-usable TDM processes as a standard step in automated test execution and CI/CD processes, finding or making rich data sets on the fly.
This leverages the types of data preparation processes currently performed annually by central Ops teams, but renders them re-usable “just in time” during automated test creation or execution. The data preparation processes are necessarily ruled based, as they must retain the integrity of the data, and they can therefore be automated. They can furthermore be combined, and performed as a standard step within automated test execution.
To implement “data allocation” during model-based test design or execution, QA teams simply need to assign the re-usable test data processes to blocks in their models. Assigning a re-usable processes to a block which also has a UFT action associated with it will define which data should be found or made to perform that action.
In Test Modeller, the test data processes are all readily available from a central catalogue, from which they are assigned at the model level: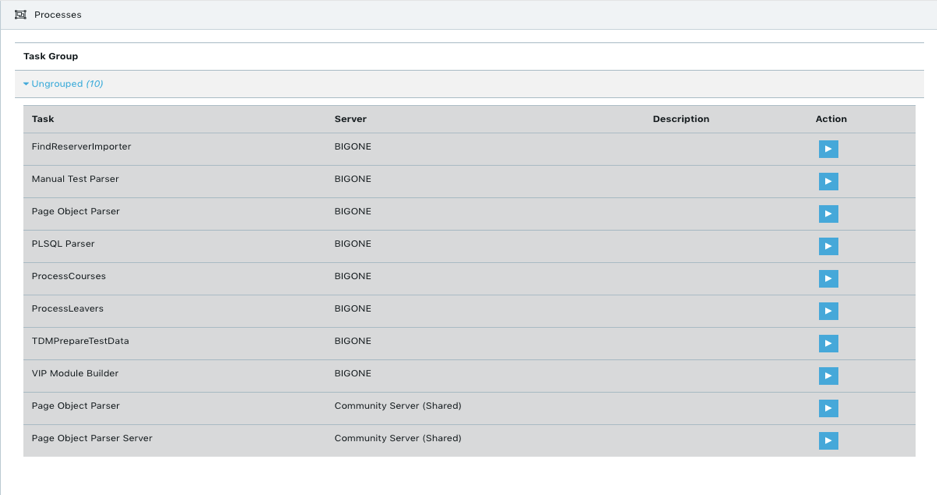
Figure 4 – A catalogue of re-usable test data processes, used to embed test data
provisioning as a standard step in UFT test automation.
In the below example, a simple test cases have been auto-generated from one such model. The model includes a re-usable TDM process called “FindMake”. This runs an automated data “Find” which hunts through back-end databases to find combinations to satisfy the relevant test case. If no data is found, it performs a “Make” to create some, rendering it re-usable to future tests.
Each test in this model has both passed and valid data has been found for each, indicating that the pass result is not a false positive: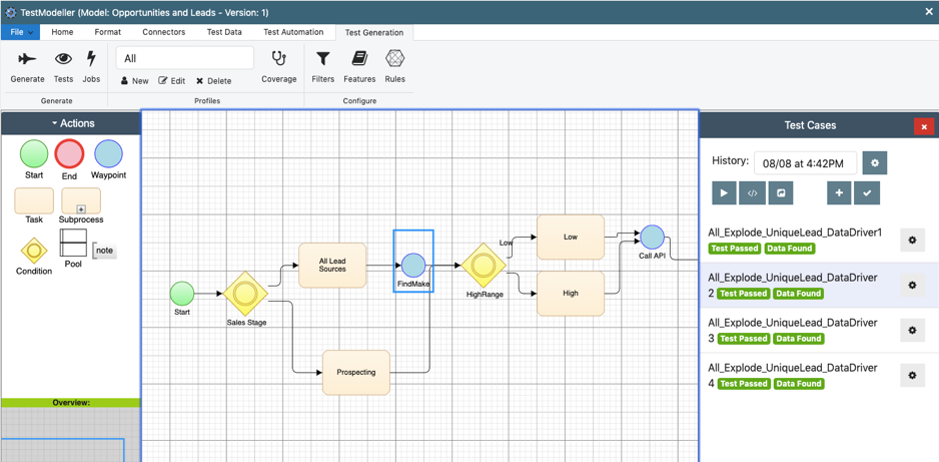
Figure 5 – A re-usable test data “Find and Make” has been embedded at the model
level, resolving just in time to find or create data for every generate test.
This approach moves from manual data preparation to just in time data “allocation”, finding and/or making accurate data combinations as automated tests run. It removes the dependency on an upstream team, effectively eradicating the delays created by data provisioning.
Data coverage analysis and automated data “makes” furthermore ensure that every test comes equipped with the data needed for optimal test coverage, while “just in time” data resolution ensures that data is valid and up-to-date.
This approach does not mean that you must define the exact combination needed for each and every test in advance: you can instead set up a data “explosion” that will recombine existing data values on-the-fly, executing tests using rich and varied test data.
Another perennial barrier to successful functional test automation adoption is manual test maintenance. Hand coded test scripts tended to be extremely brittle to changes, and break whenever an update is made to system identifiers or to the system logic. Tests then fail and automation engineers are forced to check and update their scripts.
The challenge is that complex systems require thousands of scripts, and today systems change at the speed of hourly, daily or weekly releases. Put simply, there is no time to identify manually the impact of a change across complex systems, nor to check and update every existing script within a sprint. It is no surprise, therefore, that 65% of respondents to the last World Quality Report cite the size of application change with each release as a main challenge in achieving their desired level of automation.
65% of respondents to the last World Quality Report cite the size of application change with each release as a main challenge in achieving their desired level of automation.
Automation engineers are often in turn forced to choose between letting broken regression tests pile up and creating the tests needed to validate newly committed code. Whichever they chose, impacted system logic will be left untested, exposing fast-changing systems to damaging defects.
The model-based approach set out in this article series so far generates optimised test cases, test scripts and data from central flowchart models. All the derived test assets are traceable back to these central models, and the flowcharts become the single source of truth for testing.
This traceability significantly accelerates test maintenance: if the system changes, only the logical models need updating, re-generating test scripts and data needed to test the latest picture of the system.
Updating the easy-to-maintain flowcharts is far faster than checking and updating repetitious test scripts and data by hand. Meanwhile, updating all test artefacts in one fell swoop keeps tests and data aligned, ensuring accurate test execution without the frustration of test failures caused by mismatched data: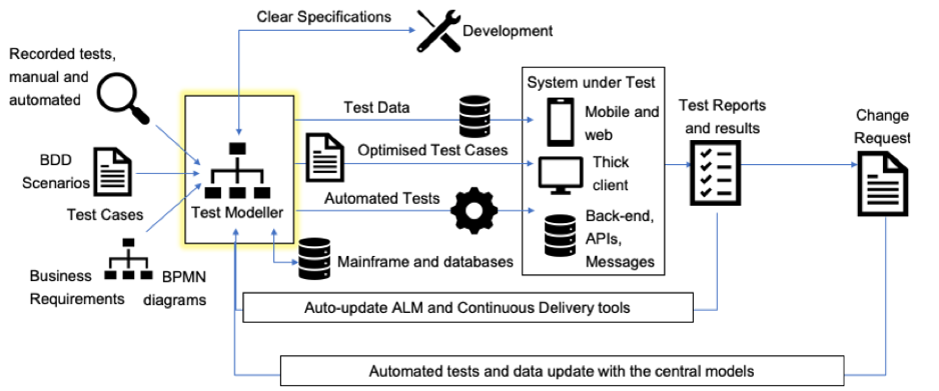
Figure 6 – Models provide a central point for generating test assets and system designs.
All assets become traceable to the model and update as new tests and requirements are
added to the models.
The automated maintenance of test assets also tends to be more reliable, working to test system changes in the same iteration in which they were introduced. With Test Modeller, a change made to one subprocess ripples across all interdependent flowcharts. Testers no longer need to speculate regarding the impact of a change across sprawling complex systems, reliably updating test suites to validate that a change has been coded successfully system wide.
Part one of this article emphasised how BPMN-style models are accessible to Business Analysts and product owners, as well as to developers, manual testers and automation engineers. Flowchart models are both simple and human readable, yet retain the formality needed to auto-generate accurate test assets.
This means that BAs and ‘manual’ testers can use the intuitive flowchart models to generate their own automated tests, as discussed in part one. It also means that the flowcharts provide a central point of communication and collaboration, serving as an “ubiquitous language” from which cross-functional teams can collaborate. This facilitates close collaboration, working from a shared picture of how the desired system should work.
This “ubiquitous language” allows testers and developers to verify that their understanding of the system matches that of the system designers and one another, avoiding the frustration, bugs, and delays caused by creating code or tests that are based on a faulty vision.
It also allows testers and developers to communicate information back to business users, for instance displaying easily understandable pass/fail results at the model level: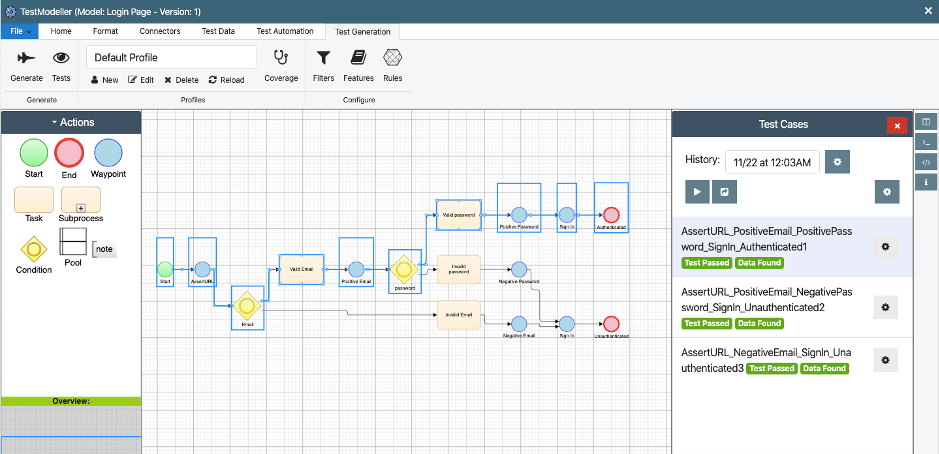
Figure 7 – Run results displayed at the model level provide a visual report of faulty system
logic.
This visual reporting allows QA to communicate to development clearly which logical paths through an application are buggy, while enabling granular root cause analysis. This leads to reduced defect remediation time, just one benefit of fostering closer collaboration between product owners and BAs, testers, and developers.
Formally modelling system requirements in flowchart models accordingly provides a point of collaboration between testers, developers and BAs. This process of modelling how the system should work further works to eliminate defects at the point where most of them arise: in the requirements.
Industry research across the years has consistently shown that the majority of bugs stem from ambiguous or incomplete requirements, and that requirements gathering accordingly also accounts for the majority of defect remediation time and cost. One paper estimates places the proportion of defects rooted in the design phase at 64%, and draws on research which finds that a bug identified during testing costs on average 15 times more to fix than one discovered during the design phase.
A primary reason for this is the nature in which fast-changing requirements are gathered, as well as the formats they are housed in. Often, requirements remain written in natural language, from monolithic requirements documents to Gherkin feature files and written user stories.
This natural language is far removed from the precise logic of the desired system that needs to be developed and tested, leaving much to chance. When a developer or tester envisions a different system, defects will enter code and tests will have false steps and incorrect expected results.
In iterative delivery and agile environments, fragmentary requirements are also coming in faster than ever, leaving testers and developers guessing the impact they have had on the system. This is because there is typically a lack of formal dependency mapping between disparate stories, diagrams, email requests, tickets, and more. Testers must instead imagine how the myriad of components contained in complex systems should interact, trying to identify the cross-system impact of a change made in one place: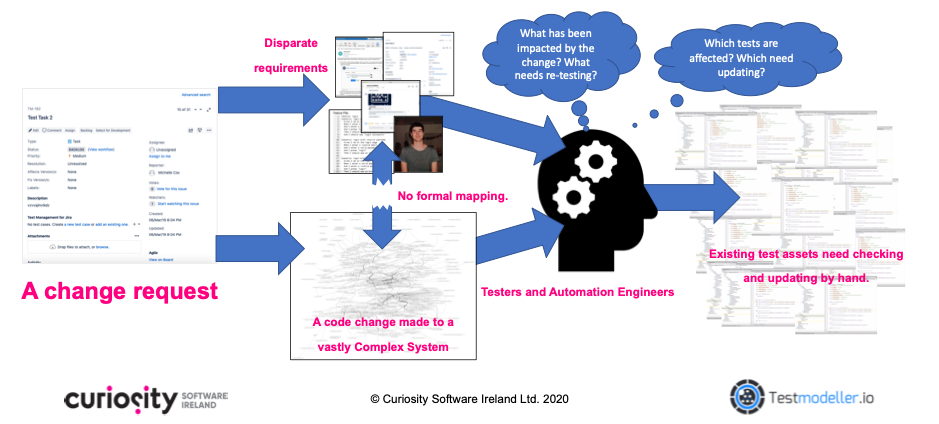
Figure 8 – The challenge of fragmentary requirements in agile development. How do we
know which part of the system they’ve impacted? How do we know which tests those
impacts have affected?
Formally modelling requirements acts as a form of requirements analysis and “shift left” QA, working to uproot misunderstandings before they can damage production systems.
Modelling requirements as flowchart models works to eradicate ambiguity. It reduces requirements into a series of “if this/then this” statements. If there are multiple ways of parsing a requirement, the singular and valid interpretation must first be decided before the model is complete.
Any missing logic is also more easily spotted in visual models, when compared to unconnected disparate written requirements and diagrams.
The requirements model in this approach act as “living documentation”, to which the latest understanding of the system is pooled. Test Modeller, for instance, imports Gherkin feature files, BPMN diagrams, recorded test activity, and more, to the central flowchart models. Otherwise fragmentary requirements and change requests can therefore be consolidated rapidly in the central models, maintaining a single source of truth as systems fast evolve.
This “living documentation” furthermore provides a reliable way to implement change requests. When a new user story or requirement is reflected in one modelled subprocess, the impact of this change will ripple across all interdependent, modelled components. Developers can then make sure they implement a change fully, working to avoid integration errors. QA, in parallel, can re-generate a targeted regression suite directly from the requirements models, rapidly creating complex end-to-end tests to validate the successful development of a change.
The re-usability and easy maintenance of requirements, test assets, and data has been a theme throughout both parts of this article. It is worth re-iterating here. Put simply, testing vastly complex and fast-changing systems in short iterations allows no time to repeat previous effort. All previous labours should be readily re-usable and malleable sprint-over-sprint, enabling testers and developers to focus on implementing newly introduced functionality.
With model-based approaches, not only test assets are made rapidly re-usable: the efforts of business analysts and product owners also deliver value immediately in testing and development. QA can take the models and requirements created as flowcharts by ‘the business’. They can then overlay re-usable UFT objects and functions from the central repository, as well as assigning the re-usable test data “find and makes” discussed earlier in this article.
Modelling thereby facilitates cross-team collaboration and seamless sharing of efforts across sprints, teams, and ‘siloes’. Business users, development, test, and ops teams can work seamlessly in parallel from one another’s efforts:
Automation engineers can live in the UFT framework, feeding new features and objects as they are needed to test new features.
Business analysts can feed new requirements into the central models, maintaining an accurate specification of what needs developing and testing.
Business analysts, product owners and testers can re-use the UFT objects and functions, overlaying them to the flowchart models to generate automated tests.
Testers and business analysts can further overlay re-usable test data processes from the central data catalogue, performing automated “finds and makes” to allocate test data to UFT tests.
Otherwise overworked and centralised teams can instead focus on building the new processes and assets needed with each iteration. Automation engineers build re-usable code for new and complex system logic, while Ops teams responsible for test data provisioning focus only on new requests.
Each person’s efforts become re-usable, empowering each member of cross-functional teams to test complex applications in tight iterations. Meanwhile independent and parallelized teams are no longer constrained by upstream or cross-team delays
Continuous testing requires transformations in people, processes, and technology. Let’s conclude this article by considering how the introduction of modelling can impact each.
First, processes and technology. This two-part article has shown how model-based UFT test maintenance can remove some of the most time-consuming processes in automated testing. Test case and UFT script generation replace the delays of repetitious coding and cumbersome test maintenance, while automated data allocation removes the bottlenecks created by data provisioning.
The same automated, systematic test creation also maximises test quality, optimising UFT tests and data to cover every distinct logical decision in a system, or to focus on a high-risk functionality.
Modelling also impacts people, the third pillar needed to unlock true quality at speed. It facilitates cross-team collaboration and communication, while maximising the re-use of existing test and requirements assets. Requirements defects and miscommunications are thereby caught earlier and at less cost to fix, while otherwise overworked teams can focus on building only the new automation needed to validate newly introduced system logic.
The result? Business analysts, product owners, manual testers and engineers can all re-use one another’s efforts in parallel, rigorously test at the rate of rapid application change.
Figure 9 – Ten reasons to consider introducing model-based testing to UFT, as set out in
this two-part article.
Thanks for reading!
If you would like to see these benefits in action, please register for the on demand Vivit Webinar, Model-Based Testing for UFT One and UFT Developer: Optimized Test Script Generation.

System models: there’s lots of different techniques today, but where is their true value for testers and developers? Here’s five ways that I’ve found...

Software development has been revolutionized by new methodologies and practices. The software industry has moved from sequential waterfall...
UI Testing is often considered the most intuitive for human testers. UIs are built for human use and testers can thus act as a human would....

Its ongoing development, including the recently introduced of the ‘UFT Family’, ensure that OpenText (Micro Focus) UFT remains one of the...

The QA community has been speaking about functional test automation for a long time now, but automated test execution rates remain too low. A major...

Welcome to Part 2/5 in our “Scalable Mobile Test Automation” series. Part 1 set out the seismic rise in mobile use, arguing that testing strategies...

Despite increasing investment in test automation, many organisations today are yet to overcome the barrier to successful automated testing. In fact,...

Test teams today are striving to automate more in order to test ever-more complex systems within ever-shorter iterations. However, the rate of test...

This is Part 3/3 of “Introducing “Functional Performance Testing”, a series of articles considering how to test automatically across multi-tier...